Installation serveur BD H2
Dans un premier temps, nous allons installer un système de gestion de bases de données. Pour palier à tous les problèmes de configuration, nous allons utiliser H2 qui est un serveur de BD très léger qui stocke la BD dans un fichier.
Si vous avez déjà un serveur de base de données, vous pouvez l'utiliser mais il faudra adapter par vous-même les fichiers de configuration d'Hibernate et les dépendences du fichier pom.xml.
Télécharger le jar de la dernière version de H2 (2.2.224) ici. Il faut cliquer sur la dernière version et ensuite sur la nouvelle page cliquer sur le petit lien jar.
Dans un terminal et dans le répertoire contenant le jar de H2, lancez le serveur H2 avec la ligne ci-dessous:
$ java -cp h2-2.2.224.jar org.h2.tools.Server -ifNotExists &
En plus du serveur de BD, vous démarrer une console permettant d'inspecter les DB accessible depuis votre navigateur. Si tout va bien, cela une fenêtre sur la console H2 doit s'ouvrir. Si ce n'est pas le cas, vous pouvez accéder à la console en allant sur http://localhost:8082/.
Pour l'instant, il n'y a aucune BD. Le serveur est configuré créer un BD vide à chaque tentative de connexion. C'est très pratique pour les tests mais à ne surtout jamais utiliser en production.
Premiers pas avec Hibernate
Créez un nouveau projet Maven.
Dans le fichier pom.xml, ajoutez les dépendances sur Hibernate ainsi qu'une dépendance un connecteur pour H2.
<dependencies>
<dependency>
<groupId>org.hibernate.orm</groupId>
<artifactId>hibernate-core</artifactId>
<version>7.0.0.Beta3</version>
</dependency>
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<version>2.3.232</version>
<scope>runtime</scope>
</dependency>
</dependencies>
Dans le répertoire resources, créez un répertoire META-INF.
Dans ce répertoire, rajoutez le fichier persistence.xml ci-dessous:
<persistence xmlns="http://java.sun.com/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence https://jakarta.ee/xml/ns/persistence/persistence_3_0.xsd"
version="2.0">
<persistence-unit name="main-persistence-unit">
<provider>org.hibernate.jpa.HibernatePersistenceProvider</provider>
<exclude-unlisted-classes>false</exclude-unlisted-classes>
<properties>
<property name="jakarta.persistence.jdbc.url"
value="jdbc:h2:tcp://localhost/~/h2DB"/>
<!-- Credentials -->
<property name="jakarta.persistence.jdbc.user"
value="sa"/>
<property name="jakarta.persistence.jdbc.password"
value=""/>
<!-- Automatic schema export -->
<property name="jakarta.persistence.schema-generation.database.action"
value="drop-and-create"/>
<!-- SQL statement logging -->
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="hibernate.highlight_sql" value="true"/>
</properties>
</persistence-unit>
</persistence>
Le fichier persistence.xml définit une persistence-unit nommée
main-persistence-unit.
<provider>org.hibernate.jpa.HibernatePersistenceProvider</provider> <exclude-unlisted-classes>false</exclude-unlisted-classes>
Le code ci-dessus indique que la persistence sera gérée par Hibernate et qu'il faut créer un mapping dans la BD pour toutes les classes annotées par @Entity.
<property name="jakarta.persistence.jdbc.url"
value="jdbc:h2:tcp://localhost/~/h2DB"/>
<!-- Credentials -->
<property name="jakarta.persistence.jdbc.user"
value="sa"/>
<property name="jakarta.persistence.jdbc.password"
value=""/>
Le code ci-dessus donne les paramètres nécessaire à JDBC pour qu'il puisse se connecter à notre serveur de BD.
Remarquez que l'on va se connecter à la BD correspondant au fichier ~/h2DB. Comme la base n'existe pas, H2 va la créer vide à notre première connexion et donner comme propriétaire l'utilisateur sa.
<!-- Automatic schema export -->
<property name="jakarta.persistence.schema-generation.database.action"
value="drop-and-create"/>
<!-- SQL statement logging -->
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="hibernate.highlight_sql" value="true"/>
Les propriétés ci-dessus sont destinées à Hibernate.La propriété jakarta.persistence.schema-generation.database.action=drop-and-create indique à Hibernate de détruire toutes les tables et les recrée au démarrage de l'application. C'est très utile pendant le développement mais bien sûr, ce n'est pas utilisé pendant la production.
Ecrivez un classe Employee.java dans le package fr.uge.jee.hibernate.employees qui complète le squelette ci-dessous avec les constructeurs, getters
et setters nécéssaires ainsi que les méthodes toString.
public class Employee {
private long id;
private String firstName;
private String lastName;
private int salary;
...
}
Completez la classe Employee pour quelle décrive le mapping dans la BD. On veut
que la table correspondante s'appelle Employees et est le schéma donné ci-dessous:

H2 convertit tous les noms de tables et de colonnes en majuscules.
Ecrivez une classe Application qui dans son main, ajoute un Employee Harry Potter payé 1000 euros par mois dans la BD.
Utiliser la console de H2 pour vérifier que la table à bien été remplie.
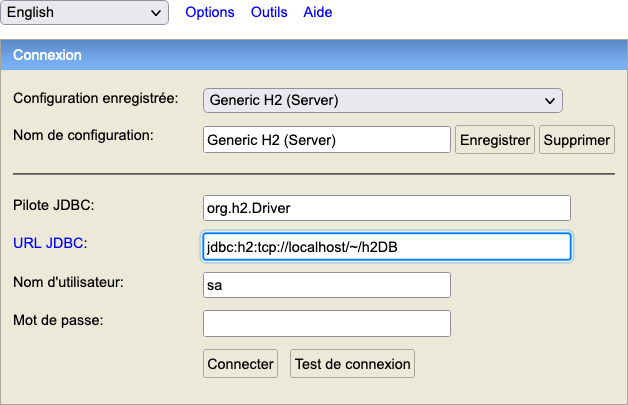
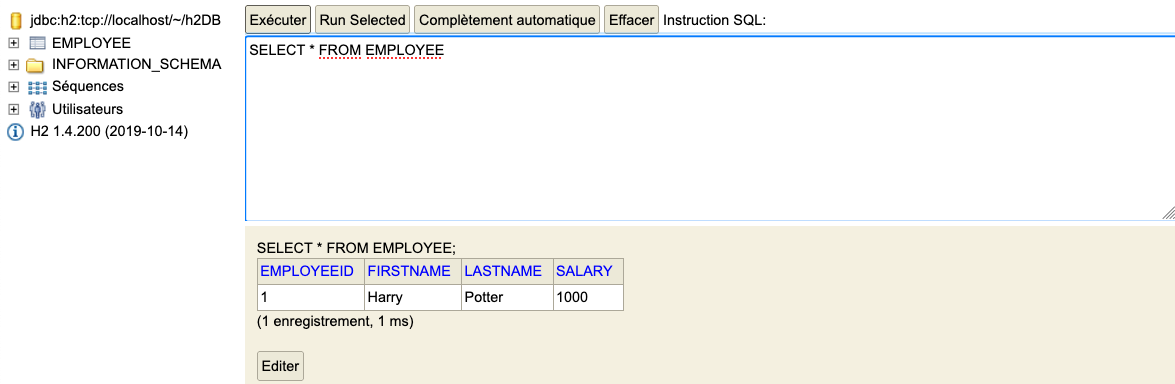
Logging des requêtes SQL (à la maison)
La propriété hibernate.show_sql=true demande à Hibernate d'afficher les requêtes SQL produit. Pour des raisons de sécurité, les paramètres des requêtes ne sont pas mis dans les logs. Pour un environement de production, c'est une bonne chose car sinon les logs contiendraient des données personnelles de nos clients. Pour le développement de l'application, il peut être pratique d'avoir accès à la totalité des requêtes SQL. Pour ce faire, nous allons passer par un proxy JDBC qui va afficher les requêtes SQL avec leur intégralité avec les paramètres.
Il faut tout d'abord rajouter le proxy P6Spy comme dépendance à notre projet Maven en mettant la dépendance ci-dessous dans le fichier pom.xml.
<dependency>
<groupId>p6spy</groupId>
<artifactId>p6spy</artifactId>
<version>3.9.1</version>
</dependency>
Dans le répertoire ressources, il faut rajouter le fichier spy.properties ci-dessous. Ce fichier donne la classe du driver pour JDBC (ici org.h2.Driver) et configure l'affichage des requêtes SQL dans les logs.
driverlist=org.h2.Driver appender=com.p6spy.engine.spy.appender.StdoutLogger logMessageFormat=com.p6spy.engine.spy.appender.CustomLineFormat customLogMessageFormat=%(category)|%(sql)
Enfin, il faut modifier le fichier persistence.xml pour utiliser P6Spy
comme ci-dessous.
<property name="jakarta.persistence.jdbc.url"value="jdbc:p6spy:h2:tcp://localhost/~/h2DB" />
Si vous avez bien suivi les instructions, vous devriez avoir les requêtes SQL complètes dans la console.
CRUD (Create, Read, Update, and Delete)
On veut maintenant réaliser une classe pour réaliser les opérations de base de persistence pour nos objets de la classe Employee.
Cette classe EmployeeRepository contient les méthodes suivantes:
public class EmployeeRepository {
private final EntityManagerFactory entityManagerFactory = ...
/**
* Create an employee with the given information
* @param firstName
* @param lastName
* @param salary
* @return the id of the newly created employee
*/
public long create(String firstName, String lastName, int salary) {
// TODO
}
/**
* Remove the employee with the given id from the DB
* @param id
* @return true if the removal was successful
*/
public boolean delete(long id) {
// TODO
}
/**
* Update the salary of the employee with the given id
* @param id
* @param salary
* @return true if the removal was successful
*/
public boolean update(long id, int salary) {
//TODO
}
/**
* Retrieve the employee with the given id
* @param id
* @return the employee wrapped in an {@link Optional}
*/
public Optional<Employee> get(long id) {
// TODO
}
/**
* Return the list of the employee in the DB
*/
public List<Employee> getAll() {
// TODO
}
}
Complétez la classe EmployeeRepository.
Toutes les méthodes de la classe EmployeeRepository vont partager énormément de code (i.e., le code créant l'EntityManager, la transaction, ... Il peut être intéressant de définir des méthodes utilitaires comme ci-dessous:
public class PersistenceUtils {
private static final EntityManagerFactory ENTITY_MANAGER_FACTORY = Persistence.createEntityManagerFactory("main-persistence-unit");
public static EntityManagerFactory getEntityManagerFactory(){
return ENTITY_MANAGER_FACTORY;
}
public static void inTransaction(Consumer<EntityManager> consumer){
...
}
public static <T> T inTransaction(Function<EntityManager,T> action){
...
}
}
Ecrivez une classe Application qui:
- crée 5 employés dans le DB: Bob Moran (500), Bob Dylan (600), Lisa Simpson (100), Marge Simpson (1000) et Homer Simpson (450),
- supprime Lisa Simpsom de BD,
- augmente le salaire de Homer Simpson de 100,
- enfin affiche tous les employées dans la base de données.
Proposez une nouvelle signature pour la méthode updateSalary qui permette de réasiler simplement:
- l'augmentation du salaire de 10%,
- ajout de 100 euros si le salaire est inférieur à 1000 euros.
Application, rajoutez 100 euros à tous les employés qui gagnent moins de 550 euros.
Rajoutez dans la classe EmployeeRepository une méthode
List<Employee> getAllByFirstName(String firstName) qui renvoie la liste des employés ayant un prénom donné.
Vous utiliserez un requête JPQL et veuillerez à ne pas être vulnérable aux attaques par injection.
Mappings uni-directionnels
Dans cet exercice, on ne vous demande de faire que des mappings uni-directionnels.
Ecrire et faire persister une classe Student qui contient:
- Une adresse représentée par une classe
Address - Une univeristé représentée par une classe
University - Une liste commentaires sur l'étudiant représentée par
List<Comment>. - L'ensemble des cours suivis par cet étudiant représenté par
Set<Lecture>
Ecrivrez des interfaces CRUD (similaires à l'exercice précédent) qui permettent:
- Créer et détruire des universités et des cours
- Rajouter un cours à un étudiant
- Changer l'université et l'adresse d'un étudiant
- Rajouter ou supprimer des commentaires sur un étudiant
- Pour un cours renvoyer la liste des étudiants qui le suive.
- Pour un étudiant renvoyer la liste de ses cours.
Chaque classe va avoir besoin de sa classe Repository, il va y avoir beaucoup de duplication de code si vous ne faites pas attention.
Mappings uni-directionnels
Reprenez le code de l'exercice précédent et transformer les mapping vers les commentaires, l'université et les cours en des mappings bi-directionnels.
Upvotes vs Downvotes
Dans cet exercice, on veut modéliser la partie base de donnée d'un site permettant de voter sur des vidéos.
On aura au minimum une classe pour les User et une classe pour les Video. On veut qu'un utilisateur puisse up-vote ou down-vote une vidéo. Attention, si un utilisateur a déjà up-vote la vidéo, il ne peut pas l'up-vote à nouveau.
Le score d'une vidéo est le nombre obtenu en soustrayant le nombre de down-votes au nombre d'up-votes. On veut que le calcul du score d'une vidéo soit le plus efficace possible.
Ecrire le code de persistence pour les deux classes User et Video. Outre les méthodes CRUD sur User et Video, on veut un moyen pour un utilisateur de up-vote et de down-vote une vidéo. L'utilisateur peut annuler son up-vote.
Essayez d'avoir le code SQL produit le plus optimal.