Ce cours de DEA est assez dense et n'a
pas été relu il est donc reservé a un public
attentif, circonspect et ayant une compétence raisonnable en
C++.
Templates
Vous trouverez cette page a l'adresse http://www-igm.univ-mlv.fr/~dr/COURS_STL/index.html
Pour plus de détails voir le cours
de C++
et plus spécialement l'écriture de
code avec des templates
La fonction suivante est générique, elle est independante du type traité:
/* fichier min.h */
template <class
comparable>
comparable
min(const comparable
&a,const comparable &b)
{
return ((a<b)
? a : b ) ;
}
Résolution par le compilateur du type:
Il est ainsi possible d'écrire
#include
``min.h''
main()
{
int i=3,j=4;
cout << min(i,j)
<< ' ' ;
cout
<< min(i,7) << ' ' ;
float
f,g=1.34;
f=
min(g,5.0);
cout
<< min(f*g,g*i) << endl;
}
Le compilateur va construire les deux fonctions min
adaptées aux besoins, c'est-à-dire int
min(int,int) et float
min(float,float) et ceci automatiquement, ceci de façon
invisible pour l'utilisateur. (d'ailleurs la plupart des compilateurs
de C++ on déjà intégré un certain nombre
de fonctions template comme min et max à la place des
macros.)
Les types non comparables :
ceux pour qui l'opérateur <
n'est pas défini
-> le compilateur
proteste
-> il faut alors définir
l'opérateur
de
préférence a l'extérieur de la classe:
class MaClass {
/*
données */
public:
friend bool operator <
(MaClass & a, MaClass & b );
/*
méthodes */
};
bool
operator < (MaClass & a, MaClass & b )
{
// code de comparaison
}
ceux pour qui la définition de l'opérateur
< est incorrecte la surcharge :
par exemple le type
(char *)
{
char
*s=''bonjour''; char *p=''zarglub'';
cout
<< min(s,p) << endl;
}
la fonction min nous retourne la
chaîne la plus basse dans la mémoire car elle compare
les pointeurs !
La surcharge du C++
résout le problème d'appel,
il
suffit de redéfinir une fonction qui spécialise le
template pour le type.
En effet cette fonction sera sélectionnée avant le template.
const char *
min(const char *a,const
char *b)
{
return (strcmp(a,b) <
0) ? a : b ;
}
char *
min(
char *a, char *b)
{
return (strcmp(a,b) <
0) ? a : b ;
}
de même pour unsigned char.
Remarque syntaxique:
unsigned différent de signed, const T différent
de T
Remarque syntaxique: attention à la signature dans laquelle
ne rentre pas le type de la valeur de retour.
Deuxième outil syntaxique: les types paramètrés
par des types.
Il est en effet difficile de travailler uniquement
avec des fonctions paramètrées par des types selon la
fameuse formule de DijkStra :
Data
Structures + algorithmes = Programmes.
Un exemple de classe template:
#include <assert.h>
const int PAS=100;
template
<class T>
class
dynArray {
public:
typedef T value_type;
union truc { int p; T
v; };
typedef
truc *pTruc;
int
nbBloc;
int
poslibre;
typedef truc bloc[PAS];
truc **global;
addBloc(){int i;
assert(poslibre== -1);
truc **temp = new pTruc[nbBloc+1];
assert(temp);
memcpy(temp,global,sizeof(pTruc)*(nbBloc));
if (global) delete global;
global = temp;
global[nbBloc]=new bloc ;
poslibre=nbBloc*PAS;
for(i=0; i <(PAS-1) ; i++)
global[nbBloc][i].p=poslibre+i+1;
global[nbBloc][PAS-1].p= -1;
nbBloc ++;
}
truc & interCrochet(int pos) {
assert((pos/PAS) <nbBloc);
return global[(pos/PAS)][(pos%PAS)];
}
public:
int libre(){ int temp;
if (poslibre == -1) { addBloc(); }
temp=poslibre;
poslibre= interCrochet(poslibre).p;
return temp;
}
void
free(int pos)
{
assert((pos>=0) && ((pos/PAS) < nbBloc) ) ;
interCrochet(pos).p = poslibre;
poslibre = pos ;
}
T &
operator [](int pos) { return interCrochet(pos).v;}
dynArray():nbBloc(0),poslibre(-1),global(0){}
~dynArray(){ while(nbBloc--) delete [] global[nbBloc]; }
};
#include <iostream.h>
main()
{
struct X { int
beurk; char coucou; } Z;
dynArray<X,10> tab; //
remarquer la syntaxe d'utilisation
int i;
int
j;
for(i=0; i <99
; i++)
{
Z.beurk =
i;
tab[tab.libre()]=Z;
}
}
Quelleque variations sur le theme:
// au lieu d'une constante
template
<class T,int PAS=100>
class
dynaArray { /* idem */ };
// attention de ne pas
multiplier les class dynaArray
// pour le même type T avec
des PAS différents
// cela entraîne une explosion de
la taille du code.
On peut voir sur cet exemple que oui, c'est agréable, mais
que c'est vite la jungle, si tout le monde se met à écrire
des template de classes formidables on ne pourra toujours pas parler
de programmation générique car non réutilisable.
D'ou la définition d'une librairie standard de templates : stl qui est dans la norme actuelle du C++.
Pour que cette librairie soit standard elle doit fournir les algorithmes de base, c'est-a-dire les structures de données les plus classiques avec les algorithmes de manipulation celles-ci.
Pour cela un certain nombre d'éléments de conception
sont interessants :
il faut que ces structures de donnée fonctionnent pour les types prédéfinis et pour les types utilisateurs.
il faut que l'on ne perde pas trop en vitesse par rapport a une implémentation directe en C, (Kerningham a dit du C qu'il etait suffisament efficace pour qu'on n'écrive plus en assembleur).
il faut pouvoir faire abstraction de l'implémentation, pour simplifier l'utilisation et pour permettre le choix de celle-ci !
il faut garder le contrôle de type même dans l'écriture générique.
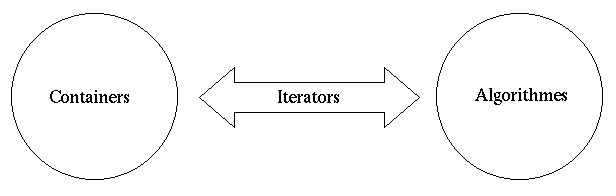
Pour répondre à ces différentes exigences Stepanov et Lee ont défini une interface à leur librairie décomposée en 3 éléments.
les containers sont une abstraction de stockage qui est
materialisée sous plusieurs formes :
- containers
séquentiels listes,deques, vecteur, (stack and queues)
-
containers associatifs map(key,value), sets, multisets(bags),
multimap(key,valueS),
par exemple vous pouvez regarder le container vector.h
voici une version expurgée de l'interface de vector
template <class T>
class vector {
public:
typedef T value_type;
private:
iterator start; // encapsulation de la memoire
iterator finish;
iterator end_of_storage;
protected:
void
insert_aux(iterator position, const T& x);
public:
iterator
begin() { return start; }
const_iterator begin() const { return start; }
iterator end() { return finish; }
const_iterator end() const { return finish; }
reverse_iterator rbegin() { return reverse_iterator(end()); }
const_reverse_iterator rbegin() const
reverse_iterator rend()
const_reverse_iterator rend() const
size_type size() const { return size_type(end() - begin()); }
size_type
max_size() const { return static_allocator.max_size(); }
size_type capacity() const { return size_type(end_of_storage -
begin()); }
bool empty() const { return begin() == end(); }
reference operator[](size_type n) { return *(begin() + n); }
const_reference operator[](size_type n) const { return *(begin() +
n); }
vector() : start(0), finish(0), end_of_storage(0) {}
vector(size_type n, const T& value = T())
vector(const vector<T>& x)
vector(const_iterator first, const_iterator last)
~vector()
vector<T>& operator=(const vector<T>& x);
void
reserve(size_type n)
reference front()
const_reference front() const
reference back()
const_reference back() const
void push_back(const T& x)
void swap(vector<T>& x)
iterator insert(iterator position, const T& x)
void insert (iterator position, const_iterator first,
const_iterator last);
void insert (iterator position, size_type n, const T& x);
void
pop_back()
void erase(iterator position)
void erase(iterator first, iterator last)
};
Cette interface genereuse permet de manipuler le vecteur.
L'interet de cette forme de vecteur c'est qu'il stocke (alloue de
la memoire) les données.
Les itérateurs ont pour objectif
d'encapsuler la notion de pointeurs de tableaux afin de pouvoir
manipuler indifféremment des tableaux du C et des containers.
C'est une idée forte car elle permet de réutiliser la
compétence acquise sur les pointeurs par de nombreux
programmeurs de C et C++. Ainsi on va pouvoir écrire la bonne
vieille formule pour strcpy avec des containers de n'importe quoi
stockés n'importe comment :
template <class
InputIterator , class OuputIterator>
void
copy(InputIterator first,
InputIterator last, OutputIterator first2)
{
while (first != last )
*first2++ = *first++ ;
}
et voilà si A et B sont des containers alors on peut écrire
:
A<T> a; // a remplir avec
quelque chose
B<T>
b; // vide on vas faire une copie bientôt
copy(a.begin(),a.end(),b.begin());
// c'est copie
la complexité de l'opération est à priori
linéaire sauf si vos containers n'ont pas un comportement
standard.
Ainsi l'algorithme de recherche suivant :
template
<class InputIterator, class T>
InputIterator find(InputIterator
first, InputIterator last, const T& value) {
while (first != last && *first != value) ++first;
return
first;
}
qui semble etre ecrit pour des tableaux du C s'utilise de la facon
suivante :
#include <iostream.h>
#include <algo.h>
#include <iterator.h>
#include <vector.h>
main()
{
// exemple avec char *
char buff[]="Bonjour";
char *fin = buff +
strlen(buff);
if (find(buff,fin, 'o'))
cout << " il y a un o " << endl ;
//
exemple avec des itérateurs de vector (qqcvd)
vector<char> vec;
int i;
for(i=0;
i < strlen(buff) ; i++)
vec.push_back(buff[i]);
if (find(vec.begin() ,
vec.end() , 'o'))
cout << " il y a un o " << endl ;
}
nous donne bien
il y a un o
il
y a un o
Regardons maintenant la déclaration de plusieurs
algorithmes
template <class
RandomAccessIterator>
void
sort(RandomAccessIterator first,
RandomAccessIterator last);
template <class
InputIterator,
class OutputIterator,
class UnaryOperation>
OutputIterator
transform(
InputIterator first,
InputIterator last,
OutputIterator result,
UnaryOperation op);
L'algorithme de tri implémenté dans sort utilise l'accès direct dans le container, il ne fonctionne donc que sur les containers qui ont ce type d'itérateurs ce qui est vrai pour les tableaux mais faux pour les listes (c'est possible mais très couteux).
D'ou le besoin de faire
une typologie des itérateurs pour ce qu'il sont capable
de fournir comme interface de déplacement :
RandomAccessIterator acces
direct it = it + n; it = it - n;
BidirectionalIterator
possibilite de faire it++; et it--;
ForwardIterator
uniquement it++;
InputIterator
iterateur de lecture
OutputIterator
iterateur d'ecriture
Utilisation générale
les
opérateurs ont pour interface
l'opérateur * qui permet de manipuler la valeur pointée.
Ce que nous avons utilisé dans le code de find.
d'autre part les opérateurs < et == sont définis (remarque).
attention avec les input itérateurs, la valeur ne peut être affectée (penser à un fichier en lecture seule), dans les ouput itérateurs il faut faire une affectation
*o_it = valeur ;
pour chaque incrémentation
o_it++;
Nous avons une forme d'héritage par compatibilité des interfaces qui est définie par le graphe d'héritage suivant:

Les algorithmes de STL sont peu nombreux
mais déjà pléthoriques.
une sélection rapide dans la page algorithmes
Leur utilisation est l'objectif premier de STL,
c'est pour les obtenir que l'ensemble de la librairie a été
définie.
Chercher dans #include
<algo.h> l'algo à votre goût.
Quelques remarques sur les paramètres
d'appels
Les objets fonctions sont des objets pour qui l'opérateur
() est défini.
struct bob {
//
carré de x inferieur a y
bool
operator () ( double &x , double & y)
{ return (x*x< y) ; }
}
// définition d'un objet fonction qui fait la somme
template <class T>
struct plus :
binary_function<T, T, T> {
T operator()(const T& x, const T& y) const { return x + y; }
};
on peut maintenant utiliser
transform(a.begin(), a.end(), b.begin(), a.begin(), plus<double>());
qui va placer dans le container a
les sommes des éléments de
a avec ceux de b
voilà, l'addition de vecteurs est terminée.
struct Zappa {
void
operator () ( int & x) { x++; }
}
;
vector<int> x;
.... // initialisation de x
for_each(x.begin(),x.end(), Zappa());