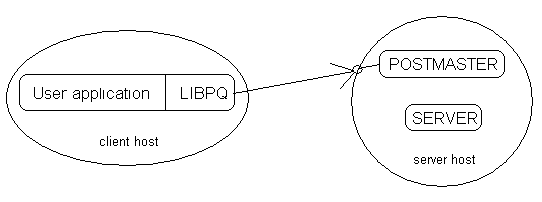
Postgres utilise un modèle client-serveur : "un processus par utilisateur".
Une session Postgres consiste en plusieurs processus UNIX coopérants:
Un seul postmaster gère l'ensemble de base de données sur un seul hôte.
Les applications en avant-plan qui veulent accéder à la base de données font appel à la librairie. Cette librairie envoie la requête de l'utilisateur à travers le réseau vers le postmaster. Le postmaster démarre un nouveau processus serveur en arrière-plan (un processus par utilisateur) et connecte ce processus au processus en avant-plan de l'application utilisateur. A partir de ce moment, les processus communiquent sans intervention du postmaster.
La librairie libpq permet à un processus en avant-plan d'établir des connexions multiples vers des processus en arrière-plan. Cependant, l'application en avant-plan est un processus "uni-thread". Les connexions avant-plan/arrière-plan multi-thread ne sont pas supportées pas lipq.
Une implication de cette architecture est que le postmaster et l'arrière-plan tourne toujours sur la même machine (le serveur de base de données), alors que les applications d'avant-plan peuvent s'exécuter n'importe où.
Dans mon exposé, c'est une
configuration monoposte : la même machine qui fait office de
serveur et de client.
L' installation a été fait sous Linux Mandrak 7.0 avec
le fichier source postgresql 7.0.2.
Vous pourriez également utiliser le package rmp qui par contre
a une version inférieure.
Pour des questions de
sécurité, utilisez toujours un compte user qui n'a
aucun droit d'administration linux pour le compte "root" de
PostgreSQL.
En root: adduser
postgres
Décompressez les par:
tar zxvf
postgresql-7.0.2.tar.gz
On vas copier les sources dans un répertoire source du
système:
mkdir /usr/src/pgsql
cp postgresql-7.0.2/*
/usr/src/pgsql -r
Passez en root ,mettre l'utilisateur postgres propriétaire de ces sources:
su root
password:
chown postgres /usr/src/pgsql -R
exit
Puis les compiler en postgres:
cd /usr/src/pgsql/src
./configure "options"
Avec pour les options par exemple:
--prefix=chemin chemin ou vous voulez installer PostgreSQL, par défaut s'installe dans /usr/local/pgsql
--enable-locale Ajoute le support des locales (support multi-langages)
--with-odbc Compile le modules ODBC
--with-tcl Ajoute le support Tcl/Tk
Une fois que le ./configure à
finis son travail et n'a renvoyé aucune érreur,
compilez les sources: make
Passez en root, tapez un : make install
puis toujours en tant que root entrez la commande: chown postgres /usr/local/pgsql
Passez en root pour ces
commandes.
On vas ajouter dans le PATH les binaires de PostgreSQL
Pour tester: toujours en tant que
root lancez le script par: /etc/rc.d/rc.local
Vérifiez que postmaster est
bien lancez par un : ps
-aux | grep postmaster
Passez maintenant en utilisateur "postgres" et lancer la commande: /usr/local/pgsql/initdb
On vas maintenant tester le bon
fonctionnement de PostgreSQL en lançant le test "regression"
fournit avec PostgreSQL.
Assurez vous d'être bien en user postgres, puis:
cd /usr/src/pgsql/src/test/regress
make all
make runtest
Vous devez voir apparaître des lignes fur et à mesure avec des OK.
On va d'abord créer une base
de données: créer des utilisateurs, créer des
tables; ensuite on crée des requêtes.
Il y a 2 modes de le faire:
des commandes en ligne (mode texte), ils ressemblent beaucoup
à ce qu'on fait en Oracle et je ne détailler pas
ici;
et mode graphique en utilisant la commande pgaccess.
Les interface langages permet aux
applications de passer les requêtes à Postgresql et de
recevoir des résultats.
Les langages compilées s'exécute plus vite que les
langages interprétés, mais ils sont plus difficiles
à programmer.
|
|
|
|
|
LIBPQ |
C |
Compilé |
Interface native |
|
LIBPGEASY |
C |
Compilé |
C simplifié |
|
ECPG |
C |
Compilé |
ANSI encastré SQL C |
|
LIBPQ++ |
C++ |
Compilé |
Orienté objet C |
|
ODCB |
ODCB |
Compilé |
Connectivité application |
|
PERL |
Perl |
Interprété |
Traitement texte |
|
PGTCLSH |
Tcl/TK |
Interprété |
Interface graphique |
|
PHP |
HTML |
Interprété |
Dynamique page Web |
|
PYTHON |
Python |
Interprété |
Orienté objet |
|
JDBC |
Java |
both |
Portabilité |
#include <stdio.h>
#include <stdlib.h> #include"libpq-fe.h"
int main (){
char section_code[3];
char query_string[256]; // contient la quête SQL
PGconn *conn; // contient la connexion
PGresult *res; // contient le résultat de requête
int i;
conn = PQconnectdb("dbname=testpg"); // connecter à la base de
données
if(PQstatus(conn) == CONNECTION_BAD){ // si la connexion est
échoué?
fprintf(stderr, "Connection to database failed.\n");
fprintf(stderr, "%s", PQerrorMessage(conn));
exit(1);
}
printf("Enter a section code:");
scanf("%s", section_code); // créer une string de
requête SQL
sprintf(query_string, "SELECT name \ FROM sectionname \ WHERE
code='%s'",section_code);
res= PQexec(conn, query_string); //envoyer la quête SQL
if(PQresultStatus(res) != PGRES_TUPLES_OK) { // si la quête est
échoué?
fprintf(stderr, "SELECT query failed.\n");
PQclear(res);
PQfinish(conn);
exit(1);
}
for(i=0; i<PQntuples(res); i++) //tous les lignes
retournées
printf("%s\n", PQgetvalue(res, i, 0));
PQclear(res); // effacer le résultat
PQfinish(conn); // déconnecter de la base de
données
return 0;
}
"Open source" implique plus que la simple diffusion du code source. La licence d'un programme open-source doit corresponde aux certains critères dont: libre redistribution, code source, travaux dérivés.
|
1977-1985 |
Ingres (RDBMS) |
University of California at Berkeley |
|
1986-1994 |
Postgres (ORDBMS) |
University of California at
Berkeley; |
|
1994-1995 |
Postgres1995 |
Jolly CHEN, Andrew YU |
|
Début 1996 |
Open Source SQL Database |
4 développeurs
initiaux + milliers de développeurs sur Internet |
|
Fin 1996 |
Postgresql |
Sortie du produit |
|
1997 |
Distribution Répandue |
Red Hat |
Les normes les plus utilisées pour les SGBD sont les normes ISO (International Standard Organisation) SQL. Celles-ci sont basé sur les normes américaines ANSI SQL.
Postgresql implémente la plupart de ces 3 normes.
Postgrsql fonctionne sur les
plates-formes suivants:
Sun Solaris, SunOs, HPUX, AIX, Linux, Irix, Digital Unix, BSDi,
NetBSD, FreeBSD, SCO Unix, NEXTSTEP, Unixware et toutes sortes
d'unix.
Un portage sur Window95/NT est en cours de réalisation.
Les performances des machines avec
CPU 32 bits décroissent rapidement quand la taille de la base
de données dépasse 5 GigaBytes.
Les machines avec CPU 32 bits imposent une limitation de 2 GB de
mémoire RAM, de 2 GB pour le système de fichier, et
d'autres limitations dues au système d'exploitation.
Si vous avez besoin d'utiliser des bases de données extrêmement grandes, il est fortement recommandé d'utiliser des machines 64 bits. Si l'on compile PostgreSQL avec un CPU 64 bits il pourra supporter d'énormes bases de données et de grosses requêtes: > 200 Gigas.
Il existe aujourd'hui plus de 20 SGBD commerciales / Internet, comme par exemple: Oracle, Sybase, Informix, IBM-DB2-unix, mysql
Postgresql a la plupart des
caractéristiques des SGBD commerciales: Transaction,
subselects, triggers, views, foreign key�
Et des fonctionnalitées en plus: user-defined types,
inheritance, rules, multi-version concurrency control.
Une grande part des applications montées sur SGBD ne peuvent se permettre d'exécuter les programmes et requêtes de leurs utilisateurs les uns après les autres, car cela impliquerait des temps d'attente beaucoup trop longs. C'est le cas, par exemple, des applications gérant les transactions boursières, les réservations de places de train ou d'avion, ... . Les SGBD doivent donc exécuter simultanément - autant que possible- les programmes et requêtes des utilisateurs. On appelle "concurrence" cette simultanéité d'exécution.
Une transaction est un mécanisme selon lequel un ensemble d'instructions SQL, ou une instruction isolée, sera traité comme une seule unité de travail.
Par défaut, chaque instruction
insert , update et delete est considérée comme une
transaction unique.
On peut regrouper, dans une transaction définie par
l'utilisateur, un ensemble d'instructions SQL à l'aide des
commandes begin transaction , commit transaction et rollback
transaction .
Toutes les instructions suivantes sont incluses dans la transaction jusqu'à une commande rollback transaction ou commit transaction .
Les transactions permettent à SQL Server de garantir :
cohérence :
les requêtes et les demandes de modification simultanées ne peuvent pas entrer en conflit ;
les utilisateurs ne voient ou ne traitent jamais des données en cours de modification.
Afin de conserver la cohérence de la base, le système doit garantir l'"atomicité" de l'exécution des transactions: toute transaction est soit complètement exécutée, soit pas du tout (All or nothing) .restauration :
en cas de panne système, la restauration de la base de données est complète et automatique.
Imaginons une base de données de comptes bancaires "bankacct". On doit effectuer un transfert de 1000F du compte A vers le compte B. La transaction doit être exprimé ainsi :
testpgsql : BEGIN WORK ;
BEGIN
testpgsql : UPDATE bankacct SET balance = balance - 1000 WHERE acctnb
= '82014' ;
UPDATE1
testpgsql : UPDATE bankacct SET balance = balance + 1000 WHERE acctnb
= '95862' ;
UPDATE1
testpgsql : COMMIT WORK;
COMMIT
La cohérence est représentée ici par 2 aspects:
la transaction doit être du
type " all or nothing". S'il
n'y a que le 1er UPDATE de fait, mais pas le 2ième, ces 1000F
disparaît de la base. Ce genre d'erreur est très
difficile à retrouver.
En cas de non exécution d'une commande (query) à cause
d'une erreur, toute la transaction est automatiquement
rollbaked.
Visibilité de la transaction. L'utilisateur ne doit jamais pouvoir voir des transactions partiellement commited. Supposons qu'on calcule la somme total des 2 comptes, juste au moment où les 1000F sont en train d'être débités d'un compte, et que le calcul est fini avant de créditer l'autre compte, le résultat sera évidemment faux.
La norme SQL92 définit quatre niveaux d'isolement pour les transactions. Chaque niveau d'isolement spécifie les types d'actions non autorisés lorsque des transactions s'exécutent simultanément.
|
|
|
|
|
Niveau 0 |
modifications en conflit |
les autres transactions modifient les données déjà modifiées par une transaction non validée .Elles peuvent cependant lire les données non validées, effectuant ainsi une lecture de données modifiées (dirty read). |
|
Niveau 1 |
les lectures de données modifiées (dirty reads) |
transaction A modifie une ligne, transaction B lit cette ligne avant que A valide la modification. Si transaction A annule la modification, les informations lues par la transaction B sont incorrectes. |
|
Niveau 2 |
les lectures uniques (non repeatable reads) |
transaction A lit une ligne, pendant que transaction B modifie cette ligne. Si transaction B valide sa modification, les lectures ultérieures par transaction A seront différents de la lecture initiale |
|
Niveau 3 |
les lectures fantômes |
transaction A lit un ensemble de lignes répondant à une condition recherchée, transaction B modifie les données. Si transaction A répète la lecture avec les mêmes conditions recherchées, elle obtient un ensemble de lignes différentes. |
|
|
|
|
|
|
|
Niveau 0 |
Read Uncommited |
Possible |
Possible |
Possible |
|
Niveau 1 |
Read Commited |
Non possible |
Possible |
Possible |
|
Niveau 2 |
Repeatable read |
Non possible |
Non possible |
Possible |
|
Niveau 3 |
Serializable |
Non possible |
Non possible |
Non possible |
Postgresql implémente 2 niveaux d'isolation: Read Commited & Serializable .
C'est le niveau d'isolation par défaut.
Principe: quand une transaction se déroule sur ce niveau, une instruction voit uniquement les données commited avant le commencement de cette instruction; elle ne voit ni de données en cours de modification ni des modifications commited durant l'exécution de cette instruction.
2 groupes d'instructions comme exemple:
|
T |
Transaction 1 |
Transaction 2 |
|
|
|
|
|
t0 |
BEGIN WORK |
BEGIN WORK |
|
t1 |
UPDATE row 34 |
� |
|
t2 |
� |
UPDATE row 34 (mis en attente) |
|
t3 |
� |
� |
|
t4 |
ROLLBACK WORK |
� |
|
t5 |
� |
UPDATE row 34 |
|
t6 |
� |
COMMIT/ROLLBACK WORK |
|
T |
Transaction 1 |
Transaction 2 |
|
|
|
|
|
t0 |
BEGIN WORK |
BEGIN WORK |
|
t1 |
UPDATE row 34 |
� |
|
t2 |
� |
UPDATE row 34 (mis en attente) |
|
t3 |
� |
� |
|
t4 |
COMMIT WORK* |
� |
|
t5 |
� |
UPDATE row 34 (ré-exécuté la condition de recherche) |
|
t6 |
� |
COMMIT/ROLLBACK WORK |
|
T |
Transaction 1 |
Transaction 2 |
|
|
|
|
|
t0 |
BEGIN WORK |
BEGIN WORK |
|
t1 |
UPDATE row 34 |
� |
|
t2 |
� |
SELECT row 34 (à état t0) |
|
t3 |
� |
� |
|
t4 |
COMMIT/ROLLBACK WORK |
� |
|
t5 |
� |
SELECT row 34 (à état t4)* |
|
t6 |
� |
COMMIT/ROLLBACK WORK |
C'est le niveau d'isolement le plus
haut. On l'obtient à l'aide de la commande:
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
Principe: quand une transaction se déroule sur ce niveau, une instruction voit uniquement les données commited avant le commencement de la transaction; elle ne voit ni de données en cours de modification ni des modifications commited durant l'exécution de la transaction.
|
T |
Transaction normale |
Transaction sérializable |
|
|
|
|
|
t0 |
BEGIN WORK |
BEGIN WORK |
|
t1 |
UPDATE row 34 |
� |
|
t2 |
� |
UPDATE row 34 (mis en attente) |
|
t3 |
� |
� |
|
t4 |
COMMIT WORK |
� |
|
t5 |
� |
Auto-ROLLBACK WORK * |
|
T |
Transaction normale |
Transaction sérializable |
|
|
|
|
|
t0 |
BEGIN WORK |
BEGIN WORK |
|
t1 |
UPDATE row 34 |
� |
|
t2 |
� |
SELECT row 34 (à état t0) |
|
t3 |
� |
� |
|
t4 |
COMMIT/ROLLBACK WORK |
� |
|
t5 |
� |
SELECT row 34 (à état t0)* |
|
t6 |
� |
COMMIT/ROLLBACK WORK |
Dans Postgresql, lecture ne bloque jamais écriture, écriture ne bloque jamais lecture.
Quels niveau on utilise?
Pourquoi Serializable?
Serializable niveau force une écécutions des
transactions de façon sérialisable, l'un après
l'autre, même les transactions sont lancées en
concurrence.
Mysql ne support pas la transaction.
Les techniques de verrouillage ont
pour principe que les transactions voulant travailler sur un
élément de la base, doivent auparavant demander
à obtenir le droit d'utiliser cet élément. Ce
droit est matérialisé par l'obtention d'un verrou.
Si l'élément n'est pas disponible pour ce type d'usage,
alors la transaction est mise en attente.
Une fois le travail effectué, la transaction libère le
verrou sur l'élément, qui devient disponible.
Verrous exclusifs
("exclusive lock", "X lock")
Définition: un verrou est dit exclusif s'il interdit toute
autre obtention d'un verrou, de quelque type que ce soit, sur
l'élément verrouillé, par une autre
transaction.
Verrous
partagés ("shared lock", "S lock")
Définition : si une transaction obtient un verrou
partagé sur un élément, une autre transaction
peut obtenir aussi un verrou partagé sur cet
élément ; mais aucune transaction ne peut obtenir de
verrou exclusif sur cet élément tant que tous les
verrous partagés ne sont pas libérés.
Interblocages
("deadlock")
des transactions qui s'attendent mutuellement.
Postgresql fournit deux niveaux de verrous: table-level et row-level.
Les verrous exclusifs sont mises
automatiquement lors de la modification d'une ligne par des
instructions UPDATE et DELETE.
Dans certain cas, on peut gérer manuellement les
vérrous. Par exemple, ajouter SELECT FOR UPDATE avant
l'instruction UPDATE afin de empêcher les modifications entre
temps.
Si Interblocage est détecté, Postgresql rollback automatique une transaction, celle qui a le moins de ressources allouées, ou celle qui a effectué le moins de mise à jour, ou la plus jeune.
|
T |
Transaction 1 |
Transaction 2 |
|
|
|
|
|
t0 |
BEGIN WORK |
BEGIN WORK |
|
t1 |
UPDATE row 34 |
UPDATE row 100 |
|
t2 |
� |
UPDATE row 34 (mis en attente) |
|
t3 |
UPDATE row 100 (mis en attente) |
� |
|
t4 |
Auto-ROLLBACK WORK |
� |
|
t5 |
� |
COMMIT WORK |
Le gestionnaire de stockage de Postgres est une collection de modules qui permettent la gestion des transactions et l'accès aux objets de la base de données. Le system de stockage a les 2 caractéristiques suivantes:
Gestion "non-overwrite"
fournir une gestion des transactions qui ne nécessite pas une grande quantité de code écrit spécialement pour la récupération des crashs. Pour cela, Postgres utilise un nouveau concept: aucune donnée n'est écrasée, toutes les modifications sont transformées en insertions: "non-overwrite". Cela signifie que les anciens enregistrements restent dans la base de données à chaque update. Cela permet une récupération plus facile des données: lors d'un crash, il ne faut pas effectuer de longues procédure de récupération car les enregistrements précédents sont immédiatement disponibles.
Time travel
Postgres maintient deux collections d'enregistrements différentes sur disque:
Pour cela, un processus asynchrone,
le vacuum cleaner a été créé. C'est lui
qui s'occupe des transfert des enregistrements dans le système
de stockage d'archives.
Il faut cependant nuancer cette vision "idyllique" car ce
système demande beaucoup de transferts vers des moyens de
stockage de données et il faudra absolument que ces transferts
soient efficaces.
Le time travel permet de garder les états antérieurs de
la base de données et aux utilisateurs d'effectuer des
recherches "historiques". Par exemple, dans une base de
données contenant les employés d'une
société, il peut être intéressant de
demander le salaire de tel employé à un certain moment.
Benchmark du 14/08/2000
Participants: Mysql et Interbase
(vient d'être open source) et 2 SGDB propriétaires.
Postgresql a gagné les tests de vitesse et de
scalabilité*, et au même niveau avec les SGDB
propriétaires dans les tests de transaction.
Conclusion: Postgresql devient aujourd'hui un SGBD viable, une
alternative aux SGBD propriétaires, et le leader des SGBD open
sources.
*scalabilité est une propriété d'un système open source: une application peut être exécutée aussi bien sur gros-systèmes que sur mini-systèmes.
Ce document est inspiré de
nombreux articles & livres sur Postgresql sur Internet.
Pour avoir une vision plus près et une compréhension
encore plus profonde, surfez-vous sur Internet.
Présentations complètes sur Postgresql
Site officile du Postgresql: http://www.postgresql.org
Base de données Postgresql: http://www.info.ucl.ac.be/BD/PostgreSQL/index.html
PostgreSQL - Introduction and Concepts , Auteur: Bruce Momjian http://www.postgresql.org/docs/aw_pgsql_book/
PostgreSQL - The PostgreSQL Development Team - Edited by Thomas Lockhart http://www.se.postgresql.org/docs/postgres/
Database-SQL-RDBMS HOW-TO pour Linux
(PostgreSQL Object Relational Database System), version
française:
http://www.freenix.fr/unix/linux/HOWTO/PostgreSQL-HOWTO.html#toc1
Postgresql - cours de l'Université Paris XII-Val de Marne http://www.univ-paris12.fr/lacl/tan/lmb/postgres.html
Great Brige: http://greatbridge.com/technologies/postgresql.php
Sujets spécifiques sur Postgresql
Plus d'information sur pgaccess: http://www.flex.ro/pgaccess/
Transactions : gestion de la cohérence des données et restauration http://lewisdj.multimania.com/sql/chap17.htm
Online Transaction Processing http://www.transarc.ibm.com/Library/documentation/txseries/4.2/aix/en_US/html/atshak/atshak08.htm
Concurrence et vérrouillage http://lbdwww.epfl.ch/f/teaching/courses/poly2/13/13.html
Benchmark
http://www.inf.enst.fr/~saglio/etudes/benchmarks.html
http://www2.linuxjournal.com/advertising/Press/2000ec_winners.html
Open Source Database Routs
Competition in New Benchmark Tests, Aug 14, 2000
http://www.greatbridge.com/about/press.php?content_id=4
MySQL Developer Contests PostgreSQL Benchmarks http://www.devshed.com/BrainDump/MySQL_Benchmarks/
Mysql
MySQL Manuel de Référence pour 3.23.3-alpha. http://serecom.univ-tln.fr/~argaud/doc/mySQL/chapitre/manual_toc.html#Credits
MySQL Benchmarks http://www.mysql.com/information/benchmarks.html