
Hurd est un ensemble de serveurs (une horde de
GNU ;)),

basé sur le micro-noyau Mach.
L'objectif principal est de reporter le maximum de
fonctionnalités sur Hurd, Mach ne s'occupant que de la gestion de
la mémoire, de l'ordonnancement des processus et de la gestion
des interruptions matérielles.
D'un point
de vue technique, l'aspect le plus intéressant de Hurd vient de
son architecture multi serveurs.
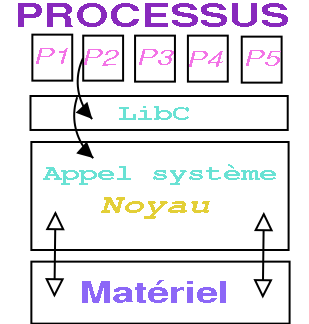
Les serveurs s'exécutent dans l'espace utilisateur, au dessus du
micro noyau, pour fournir les services aux applications.
Le système est conçu de manière très
modulaire de façon à ce que chaque composant puisse
être remplacé ou modifié. L'utilisateur a ainsi la
possibilité de changer de serveur si des besoins en ce sens se
font sentir et ce, sans mettre en péril la sécurité
ou la liberté des autres utilisateurs. Les processus dialoguent
avec le système par l'intermédiaire de
bibliothèques qui feront les appels nécessaires aux
différents serveurs (qui s'appuieront sur Mach pour tout ce
qu'ils ne pourront réaliser eux mêmes). En particulier, la
bibliothèque C implémante l'équivalent des appels
systèmes Unix. Rien n'empêche donc l'utilisateur de
remplacer ces fonctions par les siennes pour des besoins d'optimisation
ou parce que les services dont il a besoin n'existent pas.
Avec les caractérisques de transparence réseau, les
serveurs peuvent être répartis sur plusieurs machines.
Lorsqu'une nouvelle tâche est créée, le
système lui alloue des ressources sur la même machine ou
sur une machine distante.
Enfin, le code du système est réentrant. Le
système peut donc servir plusieurs requêtes
simultanément et de manière asynchrone, contrairement
l'Unix classique où le noyau ne peut fournir qu'un seul service
à la fois en suspendant les autres processus accédant au
noyau.
Point négatif : les besoins en ressources d'un tel
système sont bien plus grands en comparaison à Linux ou
à FreeBSD. Ainsi sur une machine peu puissante tel qu'un PC, sa
vivacité est sensiblement inférieure et un processeur RISC
doté de beaucoup de mémoire et de disques SCSI rapides ne
sont pas inutiles.
| Noyau Linux | Hurd |
|---|---|
| Noyau monolithique | µ-noyau |
| Mono-serveur | Multi serveurs |
| Diverses architectures | Intel 32 bits (pour l'instant ;)) |
| pour système de puissance variable |
Pour sytème puissant
|

 Très
sécurisé
Très
sécurisé Mach
est portable sur plusieurs plateformes. Hurd sera donc autant portable
que le sont Mach et GCC, et ce n'est donc pas un système
réservé au PC (même si c'est le cas pour l'instant),
mais bien un OS pouvant être implant sur à peu près
toutes les machines existantes, du micro ordinateur au super
système. Ce sont tous ces avantages qui ont justifié et
qui justifient toujours le choix de Mach comme base pour Hurd.
Mach est orienté objet et même s'il ne propose pas de
mécanismes d'héritage ou de polymorphisme, il consiste en
un ensemble d'interfaces bien définies, par lesquelles on
accède aux objets Mach : les ports, les messages, les
tâches, les threads et la mémoire virtuelle. Les
changements internes ne remettent donc pas en cause le code des
programmes les utilisant. Une des motivation de Mach est
d'émuler Unix.
Une tâche Mach correspond grossièrement à un
processus Unix. Elle correspond l'environnement d'excution reprsentant
les ressources auxquelles accès le programme, telle que la
mémoire virtuelle. À la différence d'Unix, une
tâche Mach ne contient pas implicitement un thread. Pour qu'une
tâche soit utile, il faudra donc qu'elle contienne au moins un
thread.Lesthreads Mach correspondent aux threadsdes autres
systèmes d'exploitation modernes: il s'agit d'un flot d'excution
partageant des ressources (mémoire, CPU ...) avec les autres
threads appartenant la même tâche.
Pour permettre aux différentes tâches de communiquer, Mach
fournit un mécanisme de port. Un port Mach est analogue au port
utilisé dans la programmation avec les socket: c'est un canal de
communication entre deux tâches. De la même manière
qu'avec les sockets, un port Mach permet à deux
tâches de communiquer et ce même si elles ne sont pas sur le
même processeur (cas d'un systme multiprocesseur ou sur deux
machines sparées). Et comme les ports Mach représentent le
moyen privilgié de communication entre tâches, il est
aisé de répartir les applications sur un ensembles
d'ordinateurs (passage l'échelle).
Mach présente encore de nombreuses caractéristiques, mais
elles sont moins intéressantes du point de vue de Hurd. En
s'appuyant sur Mach, Hurd bénéficie implicitement et
dès le début de ses caractéristiques temps
réel, multiprocesseurs, multithread et de la possibilité
de former des clusters transparents, contrairement aux autres
systèmes.
| Tâche | environnement d'execution |
| Thread | unité d'exécution élémentaire |
| Port | mécanisme de communication sous Mach |
| Message | communication entre thread : |
| 1)Port destination | |
| 2)Port de réponse | |
| 3)Taille du message | |
| Objet mémoire | fichier, pipe, disque |
Pour résumer et insister sur la définition des termes importants, relatifs aux notions de bases de Mach, voici un récapitulatif :
Une tâche est un environnement d'exécution (un espace mémoire virtuel) permettant d'accéder aux ressources systèmes via des ports et pouvant contenir un ou plusieurs threads.
--> Une tâche possédant un thread est l'équivalent d'un processus traditionnel Unix.
Le thread est l'unité d'exécution de base et s'exécute dans le contexte d'une tâche. Tous les threads d'une tâche partagent les ressources de cette tâche (ports, mémoire, ).
--> Les threads sont particulièrement utiles dans les applications clients serveurs(une tâche possédant plusieurs threads peut satisfaire plusieurs requêtes) et le calcul parallèle.
Les ports constituent le mécanisme de communication de base sous Mach. En effet, les communications sous effectuées en envoyant des messages vers des ports. Chacun d'eux possède des droits et une tâche doit détenir ce droit pour pouvoir envoyer un message vers un port ou recevoir un message d'un port.
--> Il existe aussi la notion d'ensemble de port (port set) qui est un groupe de ports partageant la même file de messages. Un thread peut recevoir un message d'un ensemble de port et ainsi servir plusieurs ports.
Un objet mémoire peut représenter un fichier, un pipe, ou tout autre donnée pouvant être lu ou écrite. Il représente tout objet pouvant se dans l'espace mémoire secondaire (ex: le disque).
Une tâche peut accéder à un objet mémoire en mappant la totalité ou une partie de cet objet dans son propre espace d'adressage.
Mach utilise une politique d'ordonnancement simple. En fait seuls les threads sont ordonnancés et rentrent en compétition pour obtenir des ressources ce qui signifie que les tâches n'entrent pas en jeu.
En fonction de leur utilisation du CPU, chaque thread se voit associé un numéro de priorité allant de 0 à 127. Ainsi, plus un thread utilise le CPU, plus sa priorité sera faible. On retrouve d'ailleur le même fonctionnement sous Unix et GNU/Linux.
En fonction de cette priorité, le thread sera placé dans une file d'exécution globale (visible par tous les processeurs) ou locale (visible par un seul processeur seulement et permettant de gérer les threads ne pouvant s'exécuter que sur un seul processeur).Une notion assez nouvelle et efficace pour intégrée dans ce micro noyau et celle de Quantum de temps variable. Etant donné que l'on se trouve dans un système multiprocesseur, il se peut très bien qu'il y ait à un moment donné moins de threads en cours d'exécution qu'il n'y ait de processeurs disponibles. Avec un quantum de temps fixe, un thread ayant tout épuisé son quantum de temps serait interrompu puis immédiatement ré exécuté. Les opérations de changements de contexte étant relativement coûteuse, cette façon de procéder diminuerait considérablement les performances.
Sous Mach, presque tout est objet et toute la communication est basée sur les ports et les messages.Ce système de ports et de messages permet d'assurer une transparence de la localisation des objets et une sécurité de communication. La communication sous Mach (c'est-à-dire l'échange de messages) se base sur deux caractéristiques qui sont la sécurité et la transparence. L' échange de messages se fait par le "Copy on write" : tout en préservant l'original des modifications cette technique est rapide. Pour assurer la sécurité de communication, des notions de droit sur des ports pour les envoyeurs et les receveurs. En il faut avoirla capacité d'envoyer ou de recevoir sur un port. Il est intéressant de noter qu'une seule tâche a la capacité de recevoir sur un port. Ce qui est très fort aussi concerne la possibilité de grouper plusieurs ports entre eux.
Mach n'essai pas de
réorganiser son espace d'adressage mémoire (il ne
redéplace pas les blocs mémoire pour avoir la plus grande
zone possible). Sa politique d'allocation et de
récupération mémoire est gérée par un
thread interne au noyau. L'algorithme utilisé pour
sélectionner les pages à remplacer se base sur le FIFO
avec seconde chance. Ensuite l'on se trouve à un autre niveau de
gestion de mémoire car les pages venant d'être
sélectionnées sont envoyé au gestionnaire
approprié. Ce dernier peut se situer au niveau utilisateur ce qui
permet en implémentant un algorithme de pagination
approprié d'être plus performant qu'avec le gestionnaire
par défaut. Si le gestionnaire au niveau utilisateur ne
réussit pas diminuer le nombre de pages, c'est le gestionnaire
par défaut qui est utilisé. En effet il faut veiller au
meilleur rendement possible. Lorsqu'un thread a besoin des
données d'un objet mémoire (un objet situé sur
disque), il utilise un appel système qui contient le port
identifiant l'objet en question et le gestionnaire de mémoire
utilisé. L'objet doit alors indiquer qu'il est prêt
recevoir des requètes. Si un défaut de page se produit
lorsque le thread veut accéder à cet objet
mémoire, ce thread est alors placé dans un état
d'attente. Une fois que toutes les tâches ne veulent plus envoyer
de données vers cet objet, le noyau libère le port
associé à l'objet et donc libère la mémoire
utilisée par l'objet.
L'utilisation de
mémoire partagée permet en générale une
communication interprocessus plus rapide ainsi qu'une gestion plus
aisée du multiprocesseur et de la base de données. Il est
bien sûr difficile pour des tâches situées sur des
machines différentes de partager de la mémoire. Pour
traiter ce problème, Mach utilise des gestionnaires de
mémoires externes. Ainsi si des tâches veulent partager la
même section de mémoire, ils devront utiliser le même
gestionnaire.
| serveur de crash | serveur magic | serveur de terminal |
| serveur exec | serveur new-fifo | serveur ufs |
| serveur ext2fs | serveur nfs | serveur
usermux |
| serveur fwd | serveur null | le traducteur fifo |
| serveur hostmux | serveur pfinet | le traducteur firmlink |
| serveur ifsock | serveur pflocal | le traducteur de système de fichiers ftp |
| serveur init | serveur de processus | le traducteur de lien symbolique |
| serveur de système de fichiers iso | serveur de stockage | serveur
d'authentification |
Sous les systèmes Unix classiques, l'exécution d'un programme est une suite d'étapes bien connue : l'OS réserve de la mémoire, charge l'image du binaire à partir du disque ainsi que les bibliothèques associées, procéde à une relocation du code puis lance l'exécution. Les choses se passent différemment sous Hurd. L'implantation de l'appel système execve est réparti sur plusieurs serveurs : le serveur de fichier détenant le fichier vérifie les permissions et procéde aux changements nécessaires (par exemple, si le bit setuid est posé). Un serveur exec se charge ensuite de créer une nouvelle tâche et charge l'image du programme pour lancer son exécution. En fait, plusieurs serveur exec peuvent exister sur le même système, chacun étant conçu pour supporter différents formats d'exécutables. Cela permet à Hurd d'accueillir et d'exécuter des programmes originellement développés sous d'autres systèmes voire pour d'autres machines (à la condition que le serveur exec soit capable d'émuler la machine). Les serveurs actuellement développés permettront d'exécuter des programmes pour Linux, FreeBSD, Solaris, SCO et MS-DOS.
Le serveur d'authentification :
Le serveur d'authentification permet l'authentification des utilisateurs pour les tâches désirant communiquer entre elles. Une tâche voulant vérifier l'identité d'une autre tâche se connecte sur un port du serveur d'authentification et utilise ses services. Ce serveur est donc au centre du mécanisme de sécurité de Hurd. Pour autant, il ne s'agit que d'un serveur comme les autres. Un utilisateur peut développer et exécuter son propre serveur. Les autres utilisateurs seront libres de l'utiliser s'ils lui font confiance ou de l'ignorer. Bien sûr, au démarrage, le serveur de sécurité est le seul habilité à autoriser une connexion d'un utilisateur.
Le serveur de processus :
Le serveur de processus se comporte essentiellement comme un pont entre le concept de processus Unix et le concept de tâches Mach. En effet, les tâches Mach ne fournissent pas toutes les fonctionnalités du concept POSIX des processus. Ces fonctionnalités manquantes sont fournies par le serveur de processus. Il fournit aussi des informations systèmes sur les processus. Une tâche peut ainsi s'enregistrer auprès du serveur de processus, et les autres tâches pourront obtenir des informations sur elles (cf. les commandes top et ps). Comme d'habitude, l'utilisation d'un serveur de processus est optionnelle, et un processus n'est pas obligé de s'enregistrer auprès de ce serveur. Dans ce cas, aucune information ne sera disponible à son sujet.
Le mécanisme des translators:
À la base de l'arborescence du
système de fichiers se trouve la notion de translators. Il
s'agit en fait d'un serveur particulier destiné à
réaliser les opérations possibles sur un fichier
(ouverture, lecture, écriture, ...). L'intérêt des
translators est de dissocier la notion de fichiers de celle de
données stockées sur un support. On peut donc,
grâce à une commande nommée settrans, faire en
sorte qu'un noeud quelconque de l'arborescence représente
n'importe quoi. Imaginons une archive bz2 qui se comporterait comme un
répertoire. Les programmes pourraient se déplacer dedans,
effacer ou créer des fichiers. La compilation se ferait
directement "dans" l'archive, sans que GCC ne s'aperçoive de
rien. Il faut bien comprendre que l'archive n'est pas affichée
comme un répertoire mais est un répertoire.
Mais les noeuds de l'arborescence peuvent représenter bien
d'autres choses : un SGBD ou même un processus. Il suffit alors de
lire et d'écrire dans ce fichier pour communiquer avec la
tâche, sans se préoccuper des mécanismes IPC.
Enfin, des translators destinés à gérer les
protocoles Internet sont d'ores et déjà implantés.
Le plus connu est le FTP transparent où un site FTP est
projeté dans un répertoire. L'utilisateur n'a qu'à
se déplacer à l'intérieur des
sous-répertoires et à copier les fichiers, sans avoir
à connaître la moindre commande FTP. Ce mécanisme
est prévu pour d'autres protocoles tels que HTTP et SMTP. De tels
translators utilisés avec une interface graphique telle que Motif
ou GNOME permettront d'obtenir un système réellement
intuitif et orienté utilisateur.
Enfin, il faut noter que, sauf interdiction explicite, n'importe quel
utilisateur peut poser un translator sur un noeud de l'arborescence et
bien sûr développer ses propres translators.
Conclusion