C’est la partie la plus intéressante de VMS car elle représente le pourquoi VMS. Créé pour gérer la mémoire virtuel, cet OS embarque une importante batterie d’outils algorithmiques pour la gestion de la mémoire.
Les adresses sont codées sur 32 bits. Ceci permet la gestion de 4 GO de mémoire. Pourtant, seulement 1 GO de mémoire est utilisé pour les applications. Les nouvelles versions de VMS utilisent sûrement tout l’espace restant. La mémoire est divisée en deux grandes parties :
- 0 à 2 GO : espace virtuel privé
- 2 GO à 4 GO : espace virtuel systeme.
L’espace système est partagé et les tâches utilisent la même table de pages pour traduire les adresses dans le système. Cette table est contiguë et entièrement en mémoire physique. Ceci est possible grâce au faible encombrement de l’OS (1 MO). Un registre du VAX (SBR) stocke l’entrée de cette table.
La traduction d’une adresse virtuelle dans le système suit le protocole suivant.
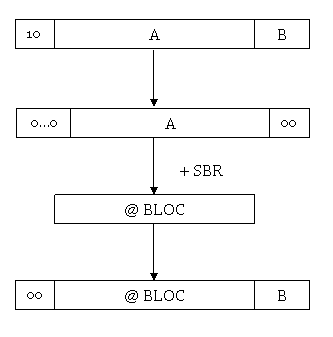 Nous avons une adresse virtuelle @ codée sur 32 bit. Cette adresse commence
par « 10 » car elle fait partie de l’espace virtuel système. Les octets
de 0 à 8 (étiquette B) permettent de pointer sur une page mémoire (512 octets).
L’étiquette A comprend donc les bits de 9 à 29.
Nous avons une adresse virtuelle @ codée sur 32 bit. Cette adresse commence
par « 10 » car elle fait partie de l’espace virtuel système. Les octets
de 0 à 8 (étiquette B) permettent de pointer sur une page mémoire (512 octets).
L’étiquette A comprend donc les bits de 9 à 29.
Prenons cette partie A et plaçons deux « 0 » à la place de la partie B et neuf « 0 » dans les derniers bits de l’adresse. Nous obtenons ainsi une adresse multiple de 4. Un déplacement en mémoire de 4 octets permet de passer d’une adresse (32 bits) à une autre.
Comme la table des pages du système est contiguë, ajoutons à la valeur du registre SBR la valeur que nous avons créé. Nous obtenons l’adresse physique d’un bloc mémoire.
Ajoutons « 00 » aux bits 30 et 31 pour nous placer dans l’espace virtuel privé et ajoutons la valeur de l’étiquette B au début de l’adresse. Nous avons reconstitué une adresse physique permettant de pointer sur la donnée voulue.
Relativement simple, cette résolution d’adresse devient plus difficile pour les adresses des données d’une tâche. Les tables de pages des tâches peuvent être très importantes. Afin d’économiser l’espace mémoire physique (faible à cette époque), elles sont stockées dans l’espace virtuel du système et peuvent donc être déplacées sur le disque. Un mécanisme complexe est alors mis en place pour retrouver les informations.
1- On prend l’étiquette A de notre adresse virtuelle @ comme ci-dessus et on l’ajoute au registre P0BR (qui stocke l’adresse de la table de pages du process). L’adresse obtenue est une adresse virtuelle de la page contenant la partie intéressante de la table de page du process.
2- A l’aide encore une fois du mécanisme ci-dessus on peut déterminer l’adresse physique de cette page dans le système.
3- On charge les données situées à cette adresse physique. La page chargée est la table de page de la tâche contenant l’adresse physique recherchée.
4- On applique donc à l’adresse récupérée la fin de l’algorithme ci-dessus car l’on a obtenu l’adresse du bloc de nos données recherchées.
Cette fois ci, le calcul est relativement compliqué et demande une certaine attention pour bien cerner le mécanisme. De plus, la traduction de l’adresse dans le cas présenté ci-dessus peut être très ralentie car par deux fois, nous avons accédé à des plages d’adresse qui peuvent être stockée sur disque (celle de la table de page du process et celle des données). Le processeur peut donc par deux fois mettre le processus de traduction en attente pour faute de page.
Le premier dispositif appelé traduction anticipée est une méthode logicielle basée sur le compteur ordinal. Lorsqu’une page est chargée en mémoire, on peut se déplacer dans cette page uniquement via les 9 premiers bits de l’adresse. Quand la requête à une instruction ne dépasse pas une page, il est possible de garder l’adresse physique que l’on utilise pour l’instruction courante et y ajouter les 9 bits du compteur ordinal. Ceci nous place donc dans la même page mémoire au bon endroit sans avoir refait tout le mécanisme de traduction d’adresse.
Le deuxième dispositif est tout simplement un tampon de traduction physique qui permet donc de stocker les précédentes traductions.
Le mécanisme de stockage est basé sur un cache disque contenant une liste de pages libres et une liste de pages modifiées. Quand le processus n’a plus de place, il libére une page et la place dans une des deux listes suivant sont état (modifié ou pas). Ceci permet deux choses :
- Lorsque le processus demande une page peu de temps après l’avoir libéré, une faute de page est levée mais il n’y a pas d’accès disque pour la recharger.
- Pour une page modifiée, elle n’est pas écrite immédiatement sur le disque ce qui permet au système d’optimiser les accès au disque.