Introduction à la sauvegarde réseau - Présentation des solutions NAS et SAN
Le contexte
Les systèmes de stockage
Définition
Une définition assez juste d'un système de stockage peut être celle-ci :Les systèmes de stockage sont un ensemble d'équipements informatiques - ordinateur, connexion réseau, médias de stockage - et de logiciels appropriés, responsables du stockage à long terme de grandes masses d'informations et de leur accès.Elle permet de rendre compte de la diversité des composants à prendre en compte, et donc du degré de complexité de telles architectures.
Historique et repères
Ce petit historique a pour vocation de donner quelques repères sur l'évolution des systèmes.En 1956, le premier stockage non volatile était fourni par le RAMAC 350 d'IBM qui permettait d'enregistrer 5 Mo dans une machine qui faisait la taille d'une pièce (quelques clichés peuvent être trouvés ici : http://www.ed-thelen.org/RAMAC/).
En 1965, on savait stocker quelques dizaines de Mo sur des bandes. En 1980 Seagate annonce le premier disque dur pour micro-ordinateur : celui-ci possède une capacité de 5 Mo.
En 1988, les premières librairies automatisées permettent la gestion de cassette de quelques centaines de Mo de capacité chacune.
Aujourd'hui, on trouve des disques durs externes d'1 To (~ 1.000.000 Mo) pour moins de 100 €.
Jacques Péping résume "l'explosion" de la quantité de données traitées dans son ouvrage Solutions de stockage en écrivant que :
Notre civilisation a produit plus d'informations durant ces 30 dernières années que pendant les 5000 ans qui les ont précédées.
Coût du stockage
Voici quelques chiffres :- 1970 : 20.000 FF/Mo
- 1998 : 2 FF/Mo
- 2004 : 0,05 FF/Mo
-
2008 : < 0,001 FF/Mo
Une explosion des données en volume comme en importance
Nous avons donc vu que plusieurs phénomènes se déroulent en parallèles.Ainsi que le coût du stockage se réduit, la capacité de stockage moyenne des systèmes est multipliée par 3,5 tous les 18 mois (augmentation supérieure à celle de la loi Moore).
Ces augmentations ont rendu possible une évolution rapide du monde de l'informatique : on citera notamment l'augmentation du nombre des postes de travail et donc de la puissance de calcul cumulée, mais aussi une augmentation de l'informatisation des tâches et de la numérisation des données.
En même temps que les informations stockées prenaient du volume, celles-ci prenaient aussi de l'importance. Ainsi, aujourd'hui, une gestion efficace et sécurisée des données est bien souvent devenue un critère déterminant pour la réussite d'une entreprise.

Toutefois, si les coûts du stockage physique des données est en diminution constante, il convient de noter qu'il n'en est pas de même pour le coût de gestion et de maintenance des systèmes, qui croissent ainsi que ceux-ci prennent de l'importance. C'est une réalité qu'il convient de ne pas sous-estimer.
Ces évolutions sont aujourd'hui une réalité, et placent les responsables des systèmes d'information face à plusieurs interrogations :
- Quel type de solution choisir ? Enregistrement sur une ou plusieurs machine ? Quel média ?
- Comment organiser les données ?
- Comment assurer la conservation et l'intégrité des données, tout en apportant une réponse aux besoins d'évolution ?
-
Comment garantir la disponibilité ?
Les systèmes de fichiers répartis
Dans un système de fichiers répartis, les informations sont distribuées sur plusieurs machines différentes, mises en réseau. On a une architecture de type client/serveur élargie : les statuts sont non exclusifs. Un client peut également être serveur d'autres machines.Un système de fichiers répartis est généralement dit virtuel car il ne fait pas apparaître l'emplacement physique des données qui est alors transparent.
Centralisation des informations et évolutions de l'accès aux fichiers
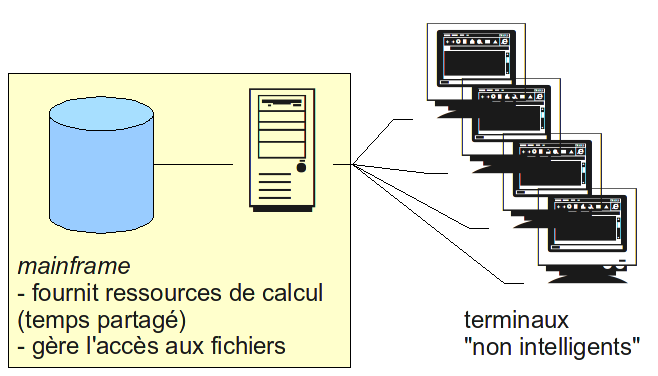
La problématique des systèmes de fichiers répartis est illustrée par la question de la centralisation de la sauvegarde et l'effet de balancier observé, reflet des évolutions des modes de travail au cours des années.Jusque dans les années 1970 les systèmes d'information déployés dans les entreprises étaient essentiellement organisés autour d'un serveur central, appelé mainframe, qui fournissait du temps de calculs ainsi qu'un espace de stockage aux terminaux non intelligents qui y étaient tous reliés. Les terminaux étaient encore assez rares.
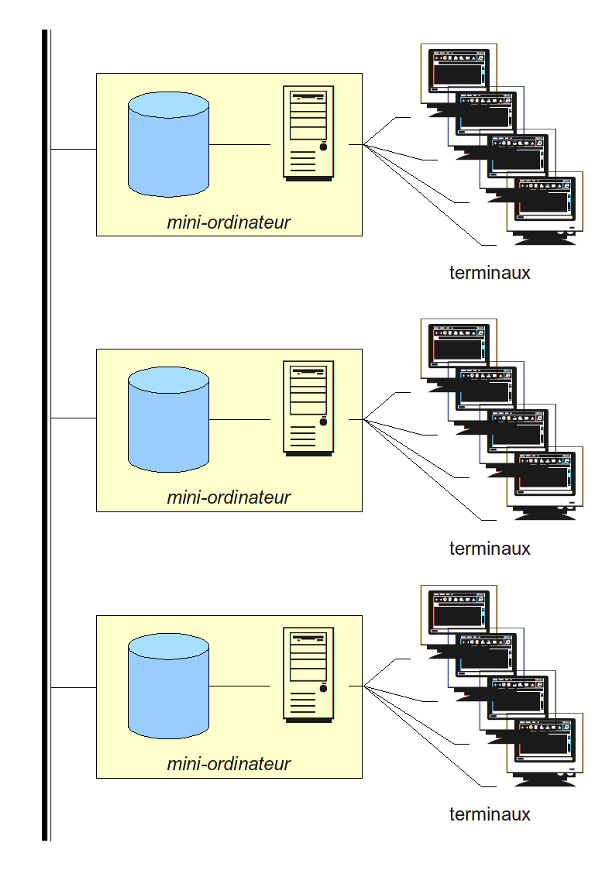
Avec le développement des systèmes et l'augmentation du nombre de terminaux, le mainframe a été remplacé par plusieurs mini-ordinateurs. Chacun d'entre eux étaient relié d'une part à une dizaine de terminaux, et d'autre part aux autres mini-ordinateurs : autorisant ainsi un échange de données, toutefois limité.
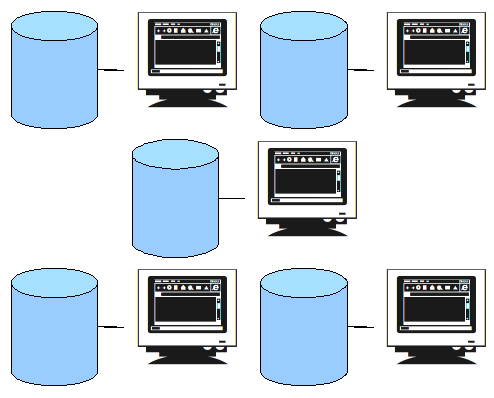
Dans les années 90, le choix s'est orienté vers la distribution de l'information sur les postes de travail personnels, chacun équipé d'unités de stockage particulières. Ceux-ci étaient d'abord autonomes, et le travail collaboratif n'était pas favorisé.
Les workgroups sont alors apparus. Ces réseaux locaux composés de plusieurs ordinateurs personnels étaient gérés sous forme d'entités d'administration, et permettaient aux employés d'un même site et d'un même service d'échanger des données.
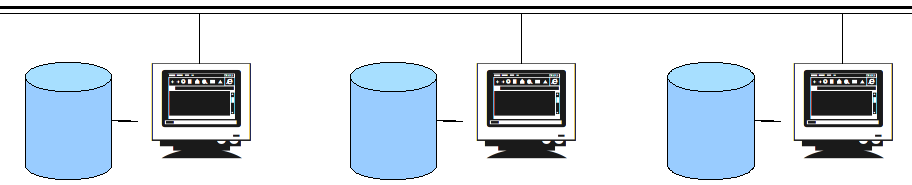
Ces réseaux ont ensuite été étendus, et sont devenus hétérogènes. Aujourd'hui les réseaux d'entreprises permettent de relier plusieurs sites géographiques indifféremment. Ces sites sont connectés grâce à des liaisons louées particulières ou même à des réseaux privés virtuels cryptés utilisant internet.
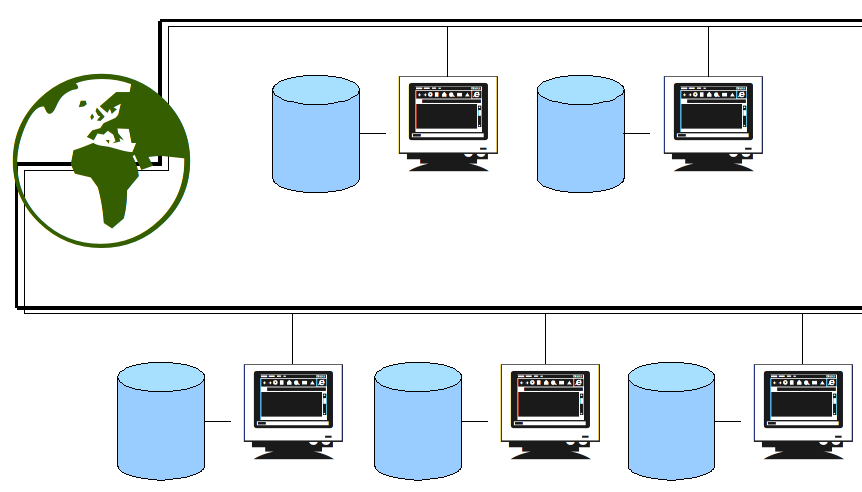
L'émergence de ces nouvelles architectures permettent l'apparition de solutions de travail collaboratives, reposant notamment sur l'utilisation de plusieurs serveurs centralisés.
Objectifs du stockage de données
Les solutions de stockage de données doivent répondre à un certain nombre d'impératifs. Si, la solution parfaite n'existe pas, ceux-ci constituent par contre des critères qu'il est important de prendre en compte pour choisir le meilleur compromis.Intégrité
La solution choisie devra permettre d'offrir une durée de vie théoriquement infinie aux données. On dit couramment que "les données doivent survivre aux incidents matériels". On pourra remplacer le matériel, les données doivent être conservées.Sécurité
La solution doit permettre d'assurer la pérennité des données. On doit savoir contrôler et tracer l'ensemble des accès aux données et les niveaux de droits associés (lecture, écriture, création, etc.).Performance
L'architecture du modèle choisi doit être dimensionnée de manière cohérente avec les performances attendues (débit, temps de latence, etc.). Ce critère est particulièrement important lorsque l'on parle de stockage réseau : il faut alors s'interroger sur les investissements nécessaires en terme d'infra-structure.Transparence
Ce critère vaut autant pour la facilité d'utilisation du système que pour la sécurité. L'utilisateur accédant aux données ne doit théoriquement pas savoir où et comment les données sont stockées, ni quels sont les accès concurrents au sien.Limitation des coûts
Pour des raisons évidentes, une bonne architecture de stockage doit permettre le stockage de grands volumes pour des coûts de mise en place et de maintenance les plus réduits possibles.Système d'information partagé
Ce terme désigne un concept un peu différent du système de fichiers répartis. L'idée est ici que les informations gérées par le système d'information, sont "partagées" de manière intelligente entre plusieurs machines/support selon des critères tels le dimensionement des infrastructures, et la performance des sous-système afin de permettre :- un faible latence pour les petits transferts ;
- un haut débit pour les transferts importants.
Calcul du MTBF
Le MTBF (Mean Time Between Failures) est un indice théorique de calcul de la durée de fonctionnement moyenne d'un système entre 2 pannes. Il est couramment utilisé lors de l'estimation du coût de maintenance de celui-ci.Il est calculé en fonctionnement dit "normal" par une formule mathématique. Une des formules utilisable est la suivante :
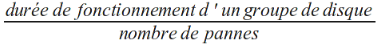
/!\ Le MTBF est donc différent de la durée de vie des disques.
Prenons un exemple :
-
soit un disque avec un MTBF d'1 million d'heures
- sa durée de vie est de quelques années
Si nous avons 1000 disques de ce type qui fonctionnent pendant 5 ans :
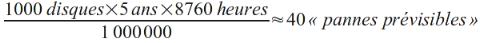
(8760 étant le nombre d'heures dans une année)
Notons que l'homogénéité du calcul est respectée !