3 COMMERCIAL IN CONFIDENCE [Top of each page; omitted hereafter] Part I Overview of GSM Security Features The object of this part of the report is to provide an overview of the security features in the GSM system. The description is brief, and focuses on the algorithms which are needed and how they are to be used: for a more detailed description the reader is referred to the GSM recommendations GSM 02.09 [2] and GSM 03.20 [3]. Three distinct security services are provided. These are subscriber identity authentication, user and signalling data confidentiality, and subscriber identity confidentiality. Each of these is considered in turn, and the mechanisms used to provide them outlined. Actually the second of the services is a grouping of three GSM features: user data confidentiality on physical connections, connectionless user data confidentiality and signalling information element confidentiality. [3]. The reason for combining them into one service is that they are all provided by one and the same mechanism. 1 Subscriber Identity Authentication This subscriber identity authentication service is the heart of the GSM security system. It is used to enable the fixed network to authenticate the identity of mobile subscribers, and to establish and manage the encryption keys needed to provide the confidentiality services. The service must be supported by all networks and mobiles, although the frequency of application is at the discretion of the network. Authentication is initiated by the fixed network, and is based upon a simple challenge-response protocol. When a mobile subscriber ( MS ) attempts to access the system, the network issues it a random challenge RAND. The MS computes a response SRES to RAND using a one-way function A3 under control of a subscriber authentication key Ki. The key Ki is unique to the subscriber, and is shared only by the subscriber and an authentication centre which serves the subscriber's home network. The value SRES computed by the MS is sig-
4 nalled to the network, where it is compared with a pre-computed value. If the two values of SRES agree, the mobile subscriber has been authenticated, and the call is allowed to proceed. If the values are different, then access is denied. The same mechanism is also used to establish a cipher key Kc for encrypt- ing user and signalling data on the radio path. This procedure is called cipher key setting in [3]. The key is computed by the MS using a one-way func- tion A8, again under control of the subscriber authentication key Ki, and is pre-computed for the network by the authentication centre which serves the subscriber's home network. Thus at the end of a successful authentication exchange, both parties possess a fresh cipher key Kc. The pre-computed triples ( RAND, SRES, Kc ), held by the fixed networks for a particular subscriber, are passed from the home network's authentication centre to visited networks upon demand. The challenges are used just once. Thus the authentication centre never sends the same triple to two distinct networks, and a network never re-uses a challenge. In practice the two functions A3 and A8 are combined into a single algo- rithm, called A38 in [2], which is used to simultaneously compute SRES and Kc from RAND and Ki. In this report this combined algorithm is referred to as the authentication algorithm. The protocol described above makes it quite clear that this algorithm need only be available to an authentication centre and the mobile subscribers which that authentication centre serves. In particular, there is no need for a common GSM authentication algorithm. and different networks may use different algorithms. ( The algorithms do, however, need to have the same input and output parameters; in particular, the length of Kc is determined by the GSM cipher algorithm ). Never-the-less it is desirable that there is a GSM standard authentication algorithm which may be used by all networks which do not wish to develop a proprietary algorithm. There is just one candidate for such an algorithm; it was proposed by the German administration, and is analysed in Part VI of this report. 2 User and Signalling Data Confidentiality As mentioned earlier, this service consists of three elements; user data confiden- tiality and signalling information on physical connections, connectionless user data confidentiality and signalling information element confidentiality. The first element provides for privacy of all user generated data, both voice and
5 non-voice, transferred over the radio path on traffic channels [2, Section 3.3]. The second element provides for privacy of user data transferred in packet mode over the radio path on a dedicated signalling channel [2. Section 3.4], whilst the third element provides for privacy of certain user related signalling elements transferred over the radio path on dedicated signalling channels [2, Section 3.5]. All of these elements of service are provided using the same layer 1 encryp- tion mechanism, and must be supported and used by all networks and mobiles. The mechanism is now briefly described. For a more comprehensive description the reader is referred to [3. Section 4]. Encryption is achieved by means of a ciphering algorithm A5 which produces a key stream under control of a cipher key Kc. This key stream is then bit-for-bit exclusive-or'd with the data trans- ferred over the radio path between the MS and the base station ( BS ). The cipher key is established at the MS as part of the authentication procedure, as described in the last section, and is transferred through the fixed network to the BS after the MS has been identified. It is essential that the MS and BS synchronise the starting of their cipher algorithms. A technique for achieving this is described in [4, Section 4], but this only directly addresses the situation when the network initiates an authen- tication check. The procedures still need to be specified in detail to cover the situation when the network does not authenticate the MS. When the network intends to issue an authentication challenge, the BS starts deciphering all data immediately after the MS has been identified using the cipher key Kc which the MS will derive upon receipt of the challenge RAND. The MS starts ciphering and deciphering the moment it has computed Kc ( and SRES ) from RAND, as described in the last section, and before SRES is transmitted. On the BS side, enciphering starts as soon as SRES has been received, deciphered and found to be correct. To cope with possible transmission loss or errors, the authentication request and response message are repeated under the control of timers. Synchronisation of the ciphering key stream is maintained by using the TDMA frame structure of the radio sub-system. The TDMA frame number is used as a message key for the cipher algorithm AS, and the algorithm produces a synchronised key stream for enciphering and deciphering the data bits in the frame. For each frame, a total of 114 bits are produced for enciphering / de- ciphering data transferred from the MS to the BS, and an additional 114 bits are produced for deciphering / enciphering data received at the MS from the BS. A frame lasts for 4.6 ms, so that the cipher has to produce the 228 bits in this time.
6 The cipher algorithm A5 must be common to all GSM networks, and three algorithms have been proposed as candidates for the GSM standard: a French algorithm, a Swedish algorithm and a UK algorithm. These algorithms are discussed in detail in subsequent parts of this report. 3 Subscriber Identity Confidentiality This service allows mobile subscribers to originate calls, update their location, etc, without revealing their International Mobile Subscriber Identity ( IMSI ) to an eavesdropper on the radio path. It thus prevents location tracing of individual mobile subscribers by listening to the signalling exchanges on the radio path. All mobiles and networks must be capable of supporting the service, but its use is not mandatory. In order to provide the subscriber identity confidentiality service it is neces- sary to ensure that the IMSI, or any information which allows an eavesdropper to derive the IMSI, it not ( normally ) transmitted in clear in any signalling message on the radio path. The mechanism used to provide this service is based on the use of a temporary mobile subscriber identity ( TMSI ), which is securely updated after each successful access to the system. Thus, in principle, the IMSI need only be transmitted in clear over the radio path at registration. In addition, the signalling elements which convey information about the IMSI are enciphered as described in the last section. The TMSI updating mechanism functions in the following manner. For simplicity, assume the MS has been allocated a TMSI, denoted by TMSIo, and the network knows the association between TMSIo and the subscriber's IMSI. The MS identifies itself to the network by sending TMSIo. Immediately after authentication ( if this takes place ), the network generates a new TMSI, denoted TMSIn, and sends this to the MS encrypted under the cipher key Kc as described in the last section. Upon receipt of the message, the MS deciphers and replaces TMSIo by TMSIn. [End first extract]
10
Part III
The French Proposal for the Cipher
The cipher proposed by France has always been considered as a hardware rather
than a software algorithm. The study of this cipher is based on the descrip-
tion reproduced in Appendix A and described in PDL ( program definition
language ) in Section 4. Software and hardware implementations of the cipher
are considered in Sections 5 and 6. The statistical tests applied are discussed
in Section 71 and there is a mathematical analysis in Section 8.
4 PDL Description of the Cipher
4.1 Main Algorithm
( Load Base Key )
FOR each base key bit from 1 to 64
Load bit into corresponding LFSR cell
END FOR
( Load Message Key )
FOR each message key bit from 1 to 22
shift_bits = f() ( Call to shift function f )
FOR each register i, from 1 to 3
Exclusive-or message key bit into lsb
IF bit i of shift_bits is set
THEN Shift
END IF
END FOR
END FOR
( Produce both enciphering and deciphering streams )
FOR i from 1 to 2
_________________________
1 The actual results from the statistical tests are in [1].
11
( Perform additional shifts )
FOR j from 1 to 100
shift_bits = f()
FOR each register k from 1 to 3
IF bit k of shift_bits is set
THEN Shift
END IF
END FOR
END FOR
( Output stream of 114 bits )
FOR J from 1 to 114
shift_bits = f()
FOR each register k from 1 to 3
IF bit k of shift_bits is set
THEN Shift
END IF
END FOR
Output = Exclusive-or msb of all three registers
END FOR
END FOR
4.2 The Shift Function f
BEGIN FUNCTION f
FOR each register i from 1 to 3
Let middle[i] = the 'middle' bit of register i
END FOR
IF less than two of the 'middle bits' are '1'
THEN bit-complement code
END IF
RETURN code
END FUNCTION
12
5 Software Estimates
In this section the cipher is described in a readable form similar to micropro-
cessor instruction code and an estimate of the speed is made from this. It was
suspected that it would not be practical to implement this code in software, so
the code was based on a very specialized microprocessor, which may not even
exist. If the cipher can not meet the time requirement of 4.6ms on the special-
ized microprocessor then it will not be able to meet it on a more general one.
This special microprocessor has a word size5 at least as long as the longest reg-
ister, i.e., 23 bits, it also has the function PARITY6 which exclusive-ors all the
bits in the accumulator and places the result in the least significant bit while
setting all the other bits to zero. Additionally it is assumed that the CARRY can
be loaded from the least significant bit of the accumulator. The problem of
directing the feedback bit to the appropriate part of the accumulator is ignored.
The external memory, considered to be arranged so that REG contains the
registers and MASK contains bit masks for both the extraction of the central
bits of each register and for the calculation of the feedback values, with the
feedback masks last and in reverse order.
The symbol & is used to mean 'address of'
5.1 Evaluating the Shift Function f
The following code extracts the central bits of each register and calculates the
corresponding output of the shift function f.
Load registers and masks
LOAD index register 1 with ®
LOAD index register 2 with &MASK
__________________________
5 Word size is considered here to be the natural size or accumulator and memory 'portions'.
6 Which will be considered as an ALU operation
13
Extract middle bits of each register
LOAD acc with MEM(index 1), POST INC index reg 1
AND acc with MEM(index 2), POST INC index reg 2
PARITY acc
STORE acc in M1
LOAD acc with MEM(index 1), POST INC index reg 1
AND acc with MEM(index 2), POST INC index reg 2
PARITY acc
STORE acc in M2
LOAD acc with MEM(index 1), POST INC index reg 1
AND acc with MEM(index 2)
PARITY acc
STORE acc in M3
Calculate shift function f
XOR acc with M2
AND acc with M1
STORE acc in I
LOAD acc with M2
AND acc with M3
OR acc with I
XOR acc with M1
STORE acc in M1
LOAD acc with I
XOR acc with M2
STORE acc in M2
LOAD acc with I
XOR acc with M3
STORE acc in M3
14
Loading the data itself requires:
2 index register operations k cycles each
Extracting the middle bits of each register requires:
6 index register operations @ k cycles each
3 ALU operations @ m cycles each
3 load / store operations @ n cycles each
The function f requires:
7 ALU operations @ m cycles each
8 load / store operations @ n cycles each
This part of the code requires 8k + 10m + 11n cycles per iteration
5.2 Performing the Shifts
The following code clocks the appropriate registers using the results of the
shift function. Note that the values of M1, M2 and M3 determine whether or
not each register is clocked. Note also that the registers are treated in reverse
order since index register 1 'points' to the contents of shift register 3 at this
stage.
LOAD acc with M3
BRANCH if zero to A
LOAD acc with MEM(index 1)
AND MEM(index 2) to acc
PARITY acc
STORE acc in CARRY
ROTATE acc right through CARRY
STORE CARRY in 03
STORE acc in MEM(index 1)
15
A: DEC index register 1
DEC index register 2
LOAD acc with M2
BRANCH if zero to B
LOAD acc with MEM(index 1)
AND MEM(index 2) to acc
PARITY acc
STORE acc in CARRY
ROTATE acc right through CARRY
STORE CARRY in 02
STORE acc in MEM(index 1)
B: DEC index register 1
DEC index register 2
LOAD acc with M1
BRANCH if zero to C
LOAD acc with MEM(index 1)
AND MEM(index 2) to acc
PARITY acc
STORE acc in CARRY
ROTATE acc right through CARRY
STORE acc in MEM(index 1)
C LOAD acc with CARRY
XOR acc with 03
XOR acc with 02
OUTPUT acc
To estimate the speed it is assumed that 9/4 of the registers are clocked on
each iteration, i e., that 3/4 of the operations to shift the registers are performed
for each iteration.
Shifting the registers requires:
3 branch operations @ j cycles each
13 index register operations @ k cycles each
6 ALU operations @ m cycles each
8 load / store operations @ n cycles each
16
The calculation of the output bit requires a further:
2 ALU operations @ m cycles each
1 load / store operation @ n cycles
Therefore, the clocking requires a total of.
3/4 x (3j + 13k + 6m + 8n) + 2m + n = 9/4j 39/4k + 13/2m + 7n
cycles per iteration.
The data loading and shift function calculation requires a further 8k +
10m + 11n cycles per iteration.
Therefore the total number of cycles required is given by:
9/4j + 71/4k + 33/2m + 18n
For typical values of j = k = 5 and m = n = 4 this gives 11.25 + 88.75 +
66 + 72 = 238 cycles per iteration.
The algorithm must be iterated 450 times to produce 228 bits of output.
This corresponds to ~~ 450 x 238 = 107100 clock cycles to produce 228 bits.
On a 1ms microprocessor this would take approximately 107 ms.
5.3 Summary
These estimates show that even on a specialized microprocessor, and ignoring
some of the detail, this cipher can not operate at the required speed. It is
therefore reasonable to assume that it would not be viable to implement this
cipher in software on a more general microprocessor.
In light of the unsuitability of this algorithm the memory requirement was
not estimated.
17
6 Hardware Estimates
The following estimates are based on the two Figures 2. and 3. Only the
hardware necessary for the shift registers and the shift function f is considered,
i.e., none of the control, interfacing or test circuitry is studied here. The overall
architecture is shown in Figure 1.
The transistor counts for various components are based on the Racal Re-
search Ltd., 2.5 mm CMOS microcell library.
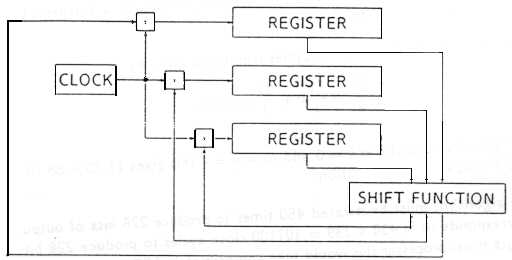 Figure 1: Overall Architecture
6.1 Notation
The elements of the circuits in Figures 2 and 3 are shown as boxes marked
with various symbols as described in the following table.
______________________________________
Symbol Function
______________________________________
MUX Multiplexor
.
_ Exclusive-or gate
.
- Exclusive-nor gate
.
. And gate
+ Or gate
Unmarked D-type, i e., register stage
______________________________________
[Symbols partly illegible]
Figure 1: Overall Architecture
6.1 Notation
The elements of the circuits in Figures 2 and 3 are shown as boxes marked
with various symbols as described in the following table.
______________________________________
Symbol Function
______________________________________
MUX Multiplexor
.
_ Exclusive-or gate
.
- Exclusive-nor gate
.
. And gate
+ Or gate
Unmarked D-type, i e., register stage
______________________________________
[Symbols partly illegible]
18
All the signals shown are single bits. However. the various "Load Control"
signals in Figure 2 are different signals which control different parts of the
loading mechanism.
6.2 Shift Registers
Figure 2 shows the register R1. The number of exclusive-or gates necessary for
each register depends upon the feedback function for that particular register;
in total seven such gates are needed for the three registers.
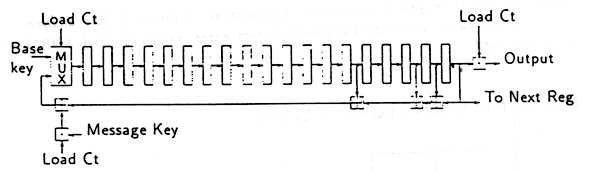 Figure 2: Shift Register Architecture for R1
[Poor original]
To load the base key, the registers are concatenated together and the key
is shifted through, suppressing the output so that the key does not reappear
again. To load the message key the key bits are exclusive-or'd into the feedback
path. In ordinary operation the feedback path is fed back to the left hand cell
without obstruction. In order to implement this a multiplexor is used to chose
between the feedback and input, while an and gate is used to suppress the
external input to the exclusive-or on the feedback path when it is not required.
The overall components together with their respective transistor counts are:
64 D-types @ 22 transistors each = 1408 transistors
6 2-input AND gates @ 6 transistors each = 36 transistors
10 XOR gates @ 10 transistors each = 100 transistors
3 2-input MUXs @ 12 transistors each = 36 transistors
1580 transistors
An additional two exclusive-or gates are required to combine the output of
the three registers, each requiring 10 transistors. This gives a total of 1600
transistors to implement the shift register.
Figure 2: Shift Register Architecture for R1
[Poor original]
To load the base key, the registers are concatenated together and the key
is shifted through, suppressing the output so that the key does not reappear
again. To load the message key the key bits are exclusive-or'd into the feedback
path. In ordinary operation the feedback path is fed back to the left hand cell
without obstruction. In order to implement this a multiplexor is used to chose
between the feedback and input, while an and gate is used to suppress the
external input to the exclusive-or on the feedback path when it is not required.
The overall components together with their respective transistor counts are:
64 D-types @ 22 transistors each = 1408 transistors
6 2-input AND gates @ 6 transistors each = 36 transistors
10 XOR gates @ 10 transistors each = 100 transistors
3 2-input MUXs @ 12 transistors each = 36 transistors
1580 transistors
An additional two exclusive-or gates are required to combine the output of
the three registers, each requiring 10 transistors. This gives a total of 1600
transistors to implement the shift register.
19
6.3 Shift function f
The shift function is implemented by producing a signal comp which is true if
the three bits M1, H2 and M3 need to be inverted. Th;s signal is the exclusive-
ored with each of the three original bits to effect the inversion. If the three bits
are regarded as numbers, then comp is true if and only if their sum is greater
than or equal to 2. Thus, if the three bits are fed into a full adder, then comp
is the negation of the carry out signal. The equation for this carry out signal
is
.
M1 .(M2 - M3) + (M2 . M3)
.
which was also employed in Section 5.1. This is shown in Figure 3. Rather than
inverting this value, and then using exclusive-or gates, exclusive-nor ( XNR )
gates are used.
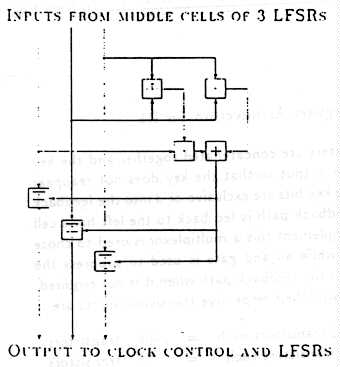 Figure 3: Shift Function f Architecture
[Poor original]
Figure 3: Shift Function f Architecture
[Poor original]
20
This requires:
2 AND gates @ 6 transistors each = 12 transistors
1 OR gate @ 6 transistors each = 6 transistors
1 XOR gate @ 10 transistors each = 10 transistors
3 XNR gates @ 10 transistors each = 30 transistors
48
In addition three further And gates are required to combine the output of
the shift function with the clock signal, see Figure 1.
The total number of transistors required is 1600 + 48 + 18 = 1666.
6.4 Speed Estimates
In order to produce the two 114-bit key streams the shift registers have to be
shifted the following number of times:
64 : to load the base key
22 : to load the message key
100 : intermediate shifts
114 : to produce the encrypt stream
100 : intermediate shifts
114 : to produce decrypt stream
514
If these shifts take two clock cycles each then 1028 clock cycles would be
required. At a clock speed of 50ns per cycle then it would take 51.4ms to
produce the key streams from the keys, which is well within the requirement.
6.5 Summary
A hardware implementation of this cipher requires a relatively small number of
transistors. approximately 1666. If the base key was loaded in parallel then
the circuitry would be more complex, however, given the speed estimate above
it is unlikely that this would be necessary.
21
These estimates suggest that it should be possible to produce a hardware
implementation of this cipher which meets the speed requirement using a
relatively small number of transistors.
[End second extract]
65
Part I
The German Proposal for the Authentication Algorithm
The authentication algorithm need not be universal and different networks are
free to use algorithms of their own choice ( provided that the parameters are
of the correct length ). However, there will be a GSM standard which can be
used by any administrations who do not wish to develop their own proprietary
algorithms. The AEG have already decided to recommend the German pro-
posal also referred to as COMP128 in some literature for this purpose. This
algorithm was included in the study in order to assess its suitability for the
task. The algorithm is specified in [8]. which is reproduced in Appendix D
( with the exception of the details of the tables ).
The functionality of the algorithm is described in PDL ( program definition
language ) in Section 20. Using this description an estimate for the complexity
of a software implementation is made in Section 21. This algorithm will even-
tually be implemented in the Subscriber Interface Module ( SIM )1 which will
be either a smart card or plug-in module. Both options for the SIM contain
a microprocessor thus the authentication algorithm will be implemented in
software rather than hardware. Therefore no hardware estimates were made
for this cipher. A brief description of the statistical analysis applied to the
algorithm is given in Section 22 and a summary of the mathematical analysis
performed is given in Section 23.
________________________________
1 See Part VII
66
20 PDL Description of the Algorithm
( Load RAND into last 16 bytes of input )
FOR i from 16 to 31
x[i] = rand[i]
END FOR
( Loop eight times )
FOR i from 1 to 8
( Load key into first 16 bytes of input )
FOR j from 0 to 15
x[j] = key[j]
END FOR
( Perform substitutions )
FOR j from 0 to 4
FOR k from 0 to 2j - 1
FOR l from 0 to 24-j - 1
m = 1 + k x 25-j
n = m +24-j
y = (x[m] + 2 x x[n]) mod 29-j
z = (2 x x[n] + x[n]) mod 29-j
x[m] = table [j,y]
x[n] = table [j,z]
END FOR
END FOR
END FOR
( Form bits from bytes )
FOR j from 0 to 31
FOR k from 0 to 7
bit [4*j+k] = the (8-k)th bit of byte j
END FOR
END FOR
67
( Permutation but not on the last loop )
IF (i < 8) THEN
FOR j from 0 to 15
FOR k from 0 to 7
next bit = (8 x j + k) x 17 mod 128
Bit k of x[j + 16] = bit[next_bit]
END FOR
END FOR
END IF
END FOR
At this stage the vector x[ ] consists of 32 nibbles. The last 8 of these
are taken as the output SRES.
21 Software Estimates
In order to estimate the complexity of a software implementation of the German
authentication algorithm, it has been described in a readable form similar to
microprocessor instruction code. This code is then used as a basis for the
estimates.
Assume that the external memory is arranged as follows:
TAB contains the compression tables.
KEY contains the 128-bit key.
SRES is 256 bits of external memory used to store the
intermediate and final values - assuming that the
last 16 bytes have been initialised with RAND.
TEMP is 16 bytes of external memory available as working space.
The symbol & is used to mean 'address of'.
68
21.1 Substitutions
The following code performs the substitutions using the tables. Note that the
indices of the j, k and l loops run 'downwards' for reasons of simplicity of
coding. The corresponding PDL segment is
FOR j from 4 to 0 step -1
FOR k from 24-j - 1 to 0 step -1
FOR l from 2j-1 to 0 step -1
m = 2j -1 - 1 + (24-j - k - 1)x (2j+l)
Code to Perform the Substitutions
LOAD index register 2 with &SRES
LOAD acc with 8
STORE acc with I
( Top of I loop )
I: LOAD acc with 16
STORE acc in J
( Load key into first 16 bytes )
A: LOAD index register 1 with &KEY
LOAD acc with MEM(index 1), POST INC index reg 1
STORE acc in MEM(index 2), POST INC index reg 2
LOAD acc with J
DEC acc
STORE acc in J
BRANCH if not zero to A
( Perform substitutions )
LOAD acc with 5
STORE acc in J
( Top of J loop )
J: DEC acc
STORE acc in J
69
STORE acc in X
LOAD acc with 1
STORE acc in T1
LOAD acc with 16
STORE acc in T2
LOAD acc with X
BRANCH if zero to C
B: LOAD acc with T1
SHIFT acc LEFT
STORE acc in T1
LOAD acc with T2
SHIFT acc RIGHT
STORE acc in T2
LOAD acc with X
DEC acc
STORE acc in X ( T1 = 2**j )
BRANCH if not zero to B ( T2 = 2**(4-j) )
C: LOAD acc with T2
STORE acc in K
( Top of K loop )
K: DEC acc
STORE acc in K
LOAD acc with T1
STORE acc in L ( L = 2**j )
( Top of L loop )
L: DEC acc
STORE acc in L
LOAD acc with T2
SUB K from acc
DEC acc
STORE acc in M
LOAD acc With J
INC acc
STORE acc in X
70
D: LOAD acc with M
SHIFT acc LEFT
STORE acc in M
LOAD acc with X
DEC acc
STORE acc in X ( M = (2**(4-j)-K-1)
BRANCH if not zero to D * 2**(J+1) )
LOAD acc with M
ADD T1 to acc
SUB L from acc
DEC acc
STORE acc in M ( M = M+(T1-L-1) )
ADD T1 to acc
STORE acc in N ( N = M + T1 )
LOAD index register 1 with &SRES
LOAD acc with M
ADD acc to index register 1
LOAD acc with MEM(index 1)
STORE acc in XM ( XM = X[M] )
LOAD index register 1 with &SRES
LOAD acc with N
ADD acc to index register 1
LOAD acc with MEM(index 1)
STORE acc in XN ( XN = X[N] )
SHIFT acc LEFT
ADD XM to acc
SHIFT acc LEFT ( Lose last bit of Y )
SHIFT acc RIGHT
STORE acc in Y ( Y = XM + 2*XW )
LOAD acc with XM
SHIFT acc LEFT
ADD XN to acc
SHIFT acc LEFT
SHIFT acc RIGHT
STORE acc in Z ( Z = 2*XM + XN )
71
LOAD index register 2 with &INDX
LOAD acc with I
ADD acc to index register 2
LOAD acc with MEM(index 2)
STORE acc in P
LOAD index register 2 with &TAB
ADD acc to index register 2 ( Point to correct
LOAD acc with Z table using INDX )
ADD acc to index register 2
LOAD acc with MEM(index 2)
STORE acc in MEM(index 1) ( table[Z] -> X[N] )
LOAD index register 1 with &SRES
LOAD acc with M
ADD acc to index register 1
LOAD index register 2 with &TAB
LOAD acc with Y
ADD acc to index register 2
LOAD acc with P ( Point to correct
ADD acc to index register 2 table using INDX )
LOAD acc with MEM(index 2)
STORE acc in MEM(index 1) ( table[Y] -> X[M] )
( Bottom of L )
LOAD acc with L
BRANCH if not zero to L
( Bottom of K )
LOAD acc with K
BRANCH if not zero to K
( Bottom of J )
LOAD acc with J
BRANCH if not zero to J
72
LOAD acc with I
DEC acc
STORE acc in I
DEC acc ( No permutation
BRANCH if zero to Z if I = 1 )
Counting the number of operations in each segment of the code gives:
Loop D 1 branch operation @ j cycles each
2 ALU operations @ m cycles each
4 load / store operations @ n cycles each
Loop L 1 branch operation @ j cycles each
21 index register operations @ k cycles each
16 ALU operations @ m cycles each
22 load / store operations @ n cycles each
Loop K 1 branch operation @ j cycles each
1 ALU operation @ m cycles each
4 load / store operations @ n cycles each
Seg C 2 load / store operations @ n cycles each
Loop B 1 branch operation @ j cycles each
3 ALU operations @ m cycles each
6 load / store operations @ n cycles each
Loop J 2 branch operation @ j cycles each
1 ALU operations @ m cycles each
8 load / store operations @ n cycles each
Loop A 1 branch operation @ j cycles each
3 index register operations @ k cycles each
1 ALU operations @ m cycles each
2 load / store operations @ n cycles each
73
In order to assess the speed of the algorithm the number of operations in
each segment of the code need to be multiplied by the number of times that
segment is performed. The code to perform the substitution contains three
nested loops J, K and L, the number of iterations of the K and L loops being
dependent on the value of the J counter, a. There are 24-a iterations of K and
2a iterations of L. Thus there are always 24-a x 2a = 24 = 16 iterations of L.
The number of iterations of each individual segment is shown in the fol-
lowing table.
__________________________________________
Nesting of Loops No of Loops Total
__________________________________________
I A 8 x 16 128
I J 8 x 5 40
I J B 8 x 5 x a 400
I J C 8 x 5 40
I J K 8 x 5 x 24-a 1240
I J K L 8 x 5 x 16 640
I J K L D 8 x 5 x 16 x (a +1) 9600
__________________________________________
This giVes the total number of cycles required to be
128(j+3k+m+2n) + 40(2j+m+8n) + 400(j+3m+6n) + 40 x 2n
+ 1240(j+m+4n) + 640(j+21k+16m+22n) + 9600(j+2m+4n)
i.e., 12080j + 13824k + 32048m + 60498n instruction cycles to
perform the substitutions.
21.2 Permutations
The following code performs the permutation. Note that although the PDL
description contains code for extracting and storing individual bits of the bytes
before permutation the low-level code here does not. What is done here is that
for each bit its corresponding byte number and bit-position within that byte
are calculated, the identified bit is masked off and the result is accumulated in
the appropriate byte.
74
Code to Perform the Permutations
LOAD index register 2 with &TEMP
LOAD acc with 16
STORE acc in J
( Top of J loop )
J1 DEC acc
STORE acc in J
LOAD acc with 0
STORE acc in M
LOAD acc with 7
STORE acc in K
( Top of K loop )
K1 DEC acc
STORE acc in K
LOAD acc with 1
STORE acc in R ( Initialize mask )
LOAD acc with J
SHIFT acc LEFT
SHIFT acc LEFT
SHIFT acc LEFT ( acc = 8*j )
ADD K to acc
STORE acc in N ( N = 8*j + K )
SHIFT acc LEFT
SHIFT acc LEFT
SHIFT acc LEFT
SHIFT acc LEFT ( acc = 16*N )
ADD N to acc
STORE acc in N ( N = 17 * (8*j + K) )
SHIFT acc LEFT
SHIFT acc RIGHT ( N = N mod 128 )
LOAD index register 1 with &SRES
LOAD acc with N
SHIFT acc RIGHT ( The required type
SHIFT acc RIGHT is INT(N/4) )
75
ADD acc to index register 1
LOAD acc with 3 ( The required bit
XOR acc with N is (N mod 4) so
STORE acc in A mask is created by
BRANCH if zero to F 3-(N mod 4) shifts )
E LOAD acc with R
SHIFT acc LEFT
STORE acc in R
LOAD acc with A
DEC acc
STORE acc in A
BRANCH if not zero to E ( Mask is now in R )
F LOAD acc with R
AND acc with MEM(index 1)
ADD acc to M ( accumulate result )
( Bottom of K loop )
LOAD acc with K
BRANCH if acc not zero to K1
LOAD acc with M
STORE acc in MEM(index 2), POST INC index reg 2
( Bottom of J loop )
LOAD acc with J
BRANCH if not zero to J1
(Copy permutation bytes into last 16 bytes in reverse order)
LOAD index register 1 with &SRES
LOAD acc with 32
ADD acc to index register 1
LOAD acc with 16
STORE acc in J
J2 LOAD acc with MEM(index 2), POST DEC index reg 2
STORE acc in MEM(index 1), POST INC index reg 1
76
LOAD acc with J
DEC acc
STORE acc in J
BRANCH if not zero to J2
( Bottom of I loop )
Z LOAD acc with I
DEC acc
BRANCH if not zero to I
Counting the number of instructions for the individual segments of code
gives:
Loop E 1 branch operation @ j cycles each
2 ALU operations @ m cycles each
4 load / store operations @ n cycles each
Loop K1 2 branch operations @ j cycles each
3 index register operations @ k cycles each
16 ALU operations @ m cycles each
11 load / store operations @ n cycles each
Loop J1 1 branch operation @ j cycles each
1 index register operation @ k cycles each
1 ALU operation @ m cycles each
7 load / store operations @ n cycles each
Loop J2 1 branch operation @ j cycles each
2 index register operations @ k cycles each
1 ALU operations @ m cycles each
2 load / store operations @ n cycles each
Other 3 index register operations @ k cycles each
5 load / store operations @ n cycles each
77
Outer Loop
Loop I 1 branch operation @ j cycles each
1 ALU operations @ m cycles each
3 load / store operations @ n cycles each
Other 1 index register operation @ k cycles each
2 load / store operations @ n cycles each
Counting the number of iterations of each segment of the code gives the
following table. Note that the permutation is not performed in the final round
of the algorithm thus the latter part of the I loop has been labelled I'.
_________________________________________
Nesting of Loops No of Loops Total
_________________________________________
I' J1 7 x 16 112
I' J1 K1 7 x 16 x 7 784
I' J1 K1 E 7 x 16 x 7 x 2 1568
I' 7 7
I' J2 7 x 16 112
I 8 8
_________________________________________
The number of iterations of the loops together with the numbers and types
of operations required by each of the loops gives the total number of instruction
cycles required to be:
112(j+k+m+7n) + 784(2j+3k+16m+11n) + 1568(j+2m+4n) +
7(3k+5n) + 112(j+2k+m+2n) + 8(j+m+3n) + k + 2n
i.e. 3368j + 2710k + 15912m + 15965n instruction cycles to perform
the permutation.
78
21.3 Speed Estimate
Adding the number of instruction cycles required for the substitutions and
permutations together gives a total of 15.456j+16.534k+47.960m+76.463n
instruction cycles to perform the algorithm. For typical values of j = k = 5
and m = n = 4, leads to a total of 657,634 instruction cycles per run.
On a 1ms processor this would require approximately 0.65s.
21.4 Memory Requirement Estimate
The code to perform the substitutions contains
72 load / store instructions @ 3 bytes each = 216 bytes
8 branch instructions @ 3 bytes each = 24 bytes
35 ALU instructions @ 1 byte each = 35 bytes
275
The code to perform the permutations contains
36 load / store instructions @ 3 bytes each = 108 bytes
6 branch instructions @ 3 bytes each = 18 bytes
23 ALU instructions @ 1 byte each = 23 bytes
149
Therefore a total of 424 bytes of memory are require to store the code.
In addition the compression tables TAB occupy 512 + 256 + 128 + 52 + 32 =
992 bytes of external memory. The variables KEY, SRES and TEMP require a
further 16 + 32 + 16 = 64 bytes of memory. In the code the following 16
single byte variables are used: A, I, J, K, L, M, N, P, R, T1, T2, X,
XM, XN, Y and Z.
Thus the total memory requirement for the data and program storage is
424 + 992 + 64 + 16 = 1072 bytes.
[End third extraction]