http.client, bas niveau
Django, Turbogears, Flask (frameworks) Zope (serveur d'applications), Plone (gestion de contenu) Bibliothèques (externes) pour SOAP, CORBA, REST ...
Fonctions de base pour lire des données à partir d'une URL. Protocoles : http, https, ftp, gopher, file.
urllib.request pour lire et écrire des URLsurllib.error contient les exceptions levées par urllib.requesturllib.parse pour analyser les URLsurllib.robotparser pour analyser les fichiers robots.txt from urllib.request import urlopen
s = urlopen('http://igm.univ-mlv.fr/~jyt/M1_python').read()
print(s)
b'<html>\n\t<body>\n\t\t<H1> M1 Informatique : Python </H1>\n\t\t<ul>\n\t\t\t<li> Commencer ici : <a href="http://www.python.org/">python.org</a>\n\t\t\t<li> La <a href="http://docs.python.org/3.8">documentation</a> officielle\n\t\t\t<li> Le <a href="http://www.pythonchallenge.com/"> Python Challenge</a>\n\t\t\t<li> <a href="https://python.developpez.com/cours/DiveIntoPython/"><i>Dive into Python</i></a> \n\t\t\tpar <a href="http://en.wikipedia.org/wiki/Mark_Pilgrim_%28software_developer%29">Mark Pilgrim</a> \n\t\t\t(un livre recommandé mais ancien);\n\t\t\t<a href="http://diveintopython3.problemsolving.io/">version Python 3</a>. \n\t\t\t<li> La <a href="http://fr.wikipedia.org/wiki/Python_%28langage%29">page</a> de Wikipédia contient un bon résumé\n\t\t\t<li> Introduction au <i>notebook</i> ipython ou jupyter :)\n\t\t\t<ul> \n\t\t\t\t<li> <a href="intro_jupyter.html">Exemple</a> de ce qu\'on peut obtenir (converti en html)\n\t\t\t\t<li> Le <a href="intro_jupyter.ipynb">code source</a> (fichier <tt>.ipynb</tt>), à télécharger\n\t\t\t\t<li> Lancer un terminal, aller dans le dossier contenant le fichier <tt>.ipynb</tt>, et entrer la commande <tt>jupyter notebook</tt>\n\t\t\t</ul>\n\t\t\t<li> Cours 1 (22/9/21) <a href="python3_M1_2021-1.html">html</a> - <a href="python3_M1_2021-1.ipynb">notebook</a>\n\t\t\t<li> <a href="td1_python3_2020.html"> TD 1</a> (22/9/21)\n\t\t\t<li> <a href="script3.py">modèle de script</a> avec options et documentation\n\t\t\t<li> <a href="td1_sol_3_2021.html">Corrigé</a> du TD 1\n\t\t\t<li> Cours 2 (29/09/2021) <a href="Python3_M1_2021-2.html">html</a> - <a href="Python3_M1_2021-2.ipynb">notebook</a>\n\t\t\t<li> <a href="td2_2021_texte.html">TD 2</a> (29/09/2021)\n\t\t\t<li> <a href="td2_solpy3_2021.html">Corrigé</a> du TD 2\n\t\t\t<li> Cours 3 (6/10/2021) <a href="python3_M1_2021-3.html">html</a> - <a href="python3_M1_2021-3.ipynb">notebook</a>\n\t\t\t<li> <a href="td3_2021_texte.html">TD 3</a> (6/10/2021)\n\n\n\n\t\t\n\n\n\t\t\t\n\n\t\t</ul>\n\t</body>\n</html>\n\n\t\t\n'
print(s.decode('ascii'))
<html> <body> <H1> M1 Informatique : Python </H1> <ul> <li> Commencer ici : <a href="http://www.python.org/">python.org</a> <li> La <a href="http://docs.python.org/3.8">documentation</a> officielle <li> Le <a href="http://www.pythonchallenge.com/"> Python Challenge</a> <li> <a href="https://python.developpez.com/cours/DiveIntoPython/"><i>Dive into Python</i></a> par <a href="http://en.wikipedia.org/wiki/Mark_Pilgrim_%28software_developer%29">Mark Pilgrim</a> (un livre recommandé mais ancien); <a href="http://diveintopython3.problemsolving.io/">version Python 3</a>. <li> La <a href="http://fr.wikipedia.org/wiki/Python_%28langage%29">page</a> de Wikipédia contient un bon résumé <li> Introduction au <i>notebook</i> ipython ou jupyter :) <ul> <li> <a href="intro_jupyter.html">Exemple</a> de ce qu'on peut obtenir (converti en html) <li> Le <a href="intro_jupyter.ipynb">code source</a> (fichier <tt>.ipynb</tt>), à télécharger <li> Lancer un terminal, aller dans le dossier contenant le fichier <tt>.ipynb</tt>, et entrer la commande <tt>jupyter notebook</tt> </ul> <li> Cours 1 (22/9/21) <a href="python3_M1_2021-1.html">html</a> - <a href="python3_M1_2021-1.ipynb">notebook</a> <li> <a href="td1_python3_2020.html"> TD 1</a> (22/9/21) <li> <a href="script3.py">modèle de script</a> avec options et documentation <li> <a href="td1_sol_3_2021.html">Corrigé</a> du TD 1 <li> Cours 2 (29/09/2021) <a href="Python3_M1_2021-2.html">html</a> - <a href="Python3_M1_2021-2.ipynb">notebook</a> <li> <a href="td2_2021_texte.html">TD 2</a> (29/09/2021) <li> <a href="td2_solpy3_2021.html">Corrigé</a> du TD 2 <li> Cours 3 (6/10/2021) <a href="python3_M1_2021-3.html">html</a> - <a href="python3_M1_2021-3.ipynb">notebook</a> <li> <a href="td3_2021_texte.html">TD 3</a> (6/10/2021) </ul> </body> </html>
urlopen renvoie un objet "file-like".
Méthodes :
read(), readline(), readlines(), fileno(), close(),
et en plus info(), geturl().
f = urlopen('http://igm.univ-mlv.fr/~jyt/M1_python')
print(dir(f))
['__abstractmethods__', '__class__', '__del__', '__delattr__', '__dict__', '__dir__', '__doc__', '__enter__', '__eq__', '__exit__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__next__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '_abc_impl', '_checkClosed', '_checkReadable', '_checkSeekable', '_checkWritable', '_check_close', '_close_conn', '_get_chunk_left', '_method', '_peek_chunked', '_read1_chunked', '_read_and_discard_trailer', '_read_next_chunk_size', '_read_status', '_readall_chunked', '_readinto_chunked', '_safe_read', '_safe_readinto', 'begin', 'chunk_left', 'chunked', 'close', 'closed', 'code', 'debuglevel', 'detach', 'fileno', 'flush', 'fp', 'getcode', 'getheader', 'getheaders', 'geturl', 'headers', 'info', 'isatty', 'isclosed', 'length', 'msg', 'peek', 'read', 'read1', 'readable', 'readinto', 'readinto1', 'readline', 'readlines', 'reason', 'seek', 'seekable', 'status', 'tell', 'truncate', 'url', 'version', 'will_close', 'writable', 'write', 'writelines']
f.code
200
f.getheaders()
[('Date', 'Sun, 10 Oct 2021 09:05:33 GMT'),
('Server', 'Apache'),
('Last-Modified', 'Wed, 06 Oct 2021 06:00:47 GMT'),
('ETag', '"1760011-7b3-5cda8de0ac1c0"'),
('Accept-Ranges', 'bytes'),
('Content-Length', '1971'),
('Connection', 'close'),
('Content-Type', 'text/html')]
f.geturl()
'http://igm.univ-mlv.fr/~jyt/M1_python/'
Pour savoir si un nouveau document a été mis en ligne
(le fichier etag_python doit avoir été initialisé) :
url = 'http://igm.univ-mlv.fr/~jyt/M1_python'
t = open('etag_python').read()
d = urlopen(url).info()
s = d['etag']
print (d['last-modified'])
if s != t :
print ("La page du cours de Python a été modifiée")
open('etag_python','w').write(s)
else: print ("Aucune modification")
Wed, 06 Oct 2021 06:00:47 GMT La page du cours de Python a été modifiée
urlopen prend un paramètre optionnel, data. Si
data est None, elle envoie une requête GET, sinon
une requête POST.
from urllib.parse import urlencode
url='http://oeis.org'
query={'q':'1,1,3,11,49,257','language':'english', 'go':'Search'}
data = urlencode(query)
data
'q=1%2C1%2C3%2C11%2C49%2C257&language=english&go=Search'
s = urlopen(url,data.encode('ascii')).read()
s[:300]
b'\n<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 3.2 Final//EN">\n<html>\n \n <head>\n <style>\n tt { font-family: monospace; font-size: 100%; }\n p.editing { font-family: monospace; margin: 10px; text-indent: -10px; word-wrap:break-word;}\n p { word-wrap: break-word; }\n </style>\n <meta http-equiv="content'
La manipulation des URLs est facilitée par le module urllib.parse
from urllib.parse import unquote, urlsplit, urlunsplit
unquote(data)
'q=1,1,3,11,49,257&language=english&go=Search'
x='http://www.google.fr/search?as_q=python&hl=fr&num=10&btnG=Recherche+Google&as_epq=&as_oq=&as_eq=&lr=&cr=&as_ft=i&as_filetype=pdf&as_qdr=all&as_occt=any&as_dt=i&as_sitesearch=univ-mlv.fr&as_rights=&safe=images'
y = urlsplit(x)
y
SplitResult(scheme='http', netloc='www.google.fr', path='/search', query='as_q=python&hl=fr&num=10&btnG=Recherche+Google&as_epq=&as_oq=&as_eq=&lr=&cr=&as_ft=i&as_filetype=pdf&as_qdr=all&as_occt=any&as_dt=i&as_sitesearch=univ-mlv.fr&as_rights=&safe=images', fragment='')
y.netloc
'www.google.fr'
y.path
'/search'
y.query
'as_q=python&hl=fr&num=10&btnG=Recherche+Google&as_epq=&as_oq=&as_eq=&lr=&cr=&as_ft=i&as_filetype=pdf&as_qdr=all&as_occt=any&as_dt=i&as_sitesearch=univ-mlv.fr&as_rights=&safe=images'
urlunsplit(y)
'http://www.google.fr/search?as_q=python&hl=fr&num=10&btnG=Recherche+Google&as_epq=&as_oq=&as_eq=&lr=&cr=&as_ft=i&as_filetype=pdf&as_qdr=all&as_occt=any&as_dt=i&as_sitesearch=univ-mlv.fr&as_rights=&safe=images'
La fonction urlopen suffit pour les applications les plus courantes.
Elle supporte les proxys pourvu qu'ils ne demandent pas d'authentification.
Il suffit de positionner les variables d'environnement
http_proxy, ftp_proxy, etc.
$ http_proxy="http://www.monproxy.com:1234" $ export http_proxy $ python
Pour un contrôle plus fin (authentification, user-agent, cookies)
on peut utiliser la classe urllib.request.Request (héritée du module
urllib2 de Python 2.
from urllib.request import Request
url='http://oeis.org'
req = Request(url)
print(dir(req))
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_data', '_full_url', '_parse', '_tunnel_host', 'add_header', 'add_unredirected_header', 'data', 'fragment', 'full_url', 'get_full_url', 'get_header', 'get_method', 'has_header', 'has_proxy', 'header_items', 'headers', 'host', 'origin_req_host', 'remove_header', 'selector', 'set_proxy', 'type', 'unredirected_hdrs', 'unverifiable']
En spécifiant les en-têtes, on peut par exemple se faire passer pour Internet Explorer
req.add_header('User-agent','Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)')
req.headers
{'User-agent': 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'}
Ou envoyer un cookie
req.add_header('Cookie', 'info=En-veux-tu%3F%20En%20voil%E0%21')
req.headers
{'User-agent': 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)',
'Cookie': 'info=En-veux-tu%3F%20En%20voil%E0%21'}
Quand on ouvre une URL, on utilise un opener. On peut
remplacer l'opener par défaut pour gérer l'authentification, les
proxys, etc. Les openers utilisent des handlers.
build_opener est utilisé pour créer des objets opener,
qui permettent d'ouvrir des URLs avec des handlers spécifiques.
Les handlers peuvent gérer des cookies, l'authentification, et autres cas communs
mais un peu spécifiques.
Les objets Opener ont une méthode open, qui peut être appelée directement
pour ouvrir des urls de la même manière que la fonction urlopen.
install_opener
peut être utilisé pour rendre l'objet opener
l'opener par défaut. Cela signifie que les appels à urlopen l'utiliseront.
Pour demander une authentification, le serveur envoie le coded'erreur 401 et un en-tête du type
www-authenticate: SCHEME realm="REALM"
Le client doit alors re-essayer la requête avec un couple (username, password)
correct pour le domaine (realm).
On peut gérer cela avec une instance de HTTPBasicAuthHandler et un
opener pour utiliser ce handler.
HTTPBasicAuthHandler utilise un "password manager"
pour gérer la correspondance entre les URIs et realms (domaines) et les
couple (password, username).
En général un seul domaine (realm) par URI : HTTPPasswordMgrWithDefaultRealm.
Exemple de la documentation officielle :
import urllib.request
# Create an OpenerDirector with support for Basic HTTP Authentication...
auth_handler = urllib.request.HTTPBasicAuthHandler()
auth_handler.add_password(realm='PDQ Application',
uri='https://mahler:8092/site-updates.py',
user='klem',
passwd='kadidd!ehopper')
opener = urllib.request.build_opener(auth_handler)
# ...and install it globally so it can be used with urlopen.
urllib.request.install_opener(opener)
urllib.request.urlopen('http://www.example.com/login.html')
Pour en savoir plus : urllib.request
Il existe un module tiers (requests) beaucoup plus pratique.
import requests
url = "http://igm.univ-mlv.fr/~jyt/secret/"
Si on essaie d'u accéder, un popup demande un nom d'utilisateur et un mot de passe.
f = urlopen(url).read()
--------------------------------------------------------------------------- HTTPError Traceback (most recent call last) <ipython-input-29-3ec16db46158> in <module> ----> 1 f = urlopen(url).read() /usr/lib/python3.8/urllib/request.py in urlopen(url, data, timeout, cafile, capath, cadefault, context) 220 else: 221 opener = _opener --> 222 return opener.open(url, data, timeout) 223 224 def install_opener(opener): /usr/lib/python3.8/urllib/request.py in open(self, fullurl, data, timeout) 529 for processor in self.process_response.get(protocol, []): 530 meth = getattr(processor, meth_name) --> 531 response = meth(req, response) 532 533 return response /usr/lib/python3.8/urllib/request.py in http_response(self, request, response) 638 # request was successfully received, understood, and accepted. 639 if not (200 <= code < 300): --> 640 response = self.parent.error( 641 'http', request, response, code, msg, hdrs) 642 /usr/lib/python3.8/urllib/request.py in error(self, proto, *args) 567 if http_err: 568 args = (dict, 'default', 'http_error_default') + orig_args --> 569 return self._call_chain(*args) 570 571 # XXX probably also want an abstract factory that knows when it makes /usr/lib/python3.8/urllib/request.py in _call_chain(self, chain, kind, meth_name, *args) 500 for handler in handlers: 501 func = getattr(handler, meth_name) --> 502 result = func(*args) 503 if result is not None: 504 return result /usr/lib/python3.8/urllib/request.py in http_error_default(self, req, fp, code, msg, hdrs) 647 class HTTPDefaultErrorHandler(BaseHandler): 648 def http_error_default(self, req, fp, code, msg, hdrs): --> 649 raise HTTPError(req.full_url, code, msg, hdrs, fp) 650 651 class HTTPRedirectHandler(BaseHandler): HTTPError: HTTP Error 401: Authorization Required
r = requests.get(url,auth=('jyt','toto'))
r.status_code
200
r.text
"<html>\n\nIl n'y a rien a voir ici ...\n</html>\n"
r.headers
{'Date': 'Sun, 10 Oct 2021 09:15:29 GMT', 'Server': 'Apache', 'Last-Modified': 'Sun, 14 Oct 2012 16:46:23 GMT', 'ETag': '"1b2e2c6-2d-4cc07a93c95c0"', 'Accept-Ranges': 'bytes', 'Content-Length': '45', 'Keep-Alive': 'timeout=15, max=100', 'Connection': 'Keep-Alive', 'Content-Type': 'text/html'}
Les modules http.server et cgi permettent de mettre en place un serveur web opérationnel en quelques lignes.
En fait, en une ligne :
[jyt@scriabine ~]$ python -m http.server Serving HTTP on 0.0.0.0 port 8000 (http://0.0.0.0:8000/) ... 127.0.0.1 - - [07/Oct/2019 09:35:32] "GET / HTTP/1.1" 200 - ...
Et sous forme de programme :
import http.server
import socketserver
PORT = 8000
Handler = http.server.SimpleHTTPRequestHandler
with socketserver.TCPServer(("", PORT), Handler) as httpd:
print("serving at port", PORT)
httpd.serve_forever()
httpd.serve_forever()
Un serveur de scripts minimal serait
#!/usr/bin/env python
import http.server
PORT = 8888
server_address = ("", PORT)
server = http.server.HTTPServer
handler = http.server.CGIHTTPRequestHandler
handler.cgi_directories = ["/"]
print("Serving on port:", PORT)
httpd = server(server_address, handler)
httpd.serve_forever()
Le script cgi devra être placé dans un sous-répertoire cgi-bin, et le serveur devra avoir le droit d'exécution. Seul root peut lancer le serveur sur le port 80. En tant qu'utilisateur normal, on pourra le lancer sur un port libre, par exemple 8888. Le formulaire sera alors déclaré avec l'action
ACTION="http://127.0.01:8888/cgi-bin/monscript.cgi"
Pour extraire des informations d'une page web, on peut parfois se débrouiller avec des expressions régulières.
Mais on a aussi souvent besoin d'une analyse complète.
Il existe pour cela un module
html.parser
qui exporte une classe HTMLParser.
On l'illustrera sur un exemple tiré de la première édition de "Dive into Python" : traduire à la volée des pages web dans des dialectes farfelus tels que ceux proposés ici.
On trouvera dans le livre de Pilgrim des grammaires simple pour chef, fudd, olde. Les textes sont supposés en anglais, donc en ASCII.
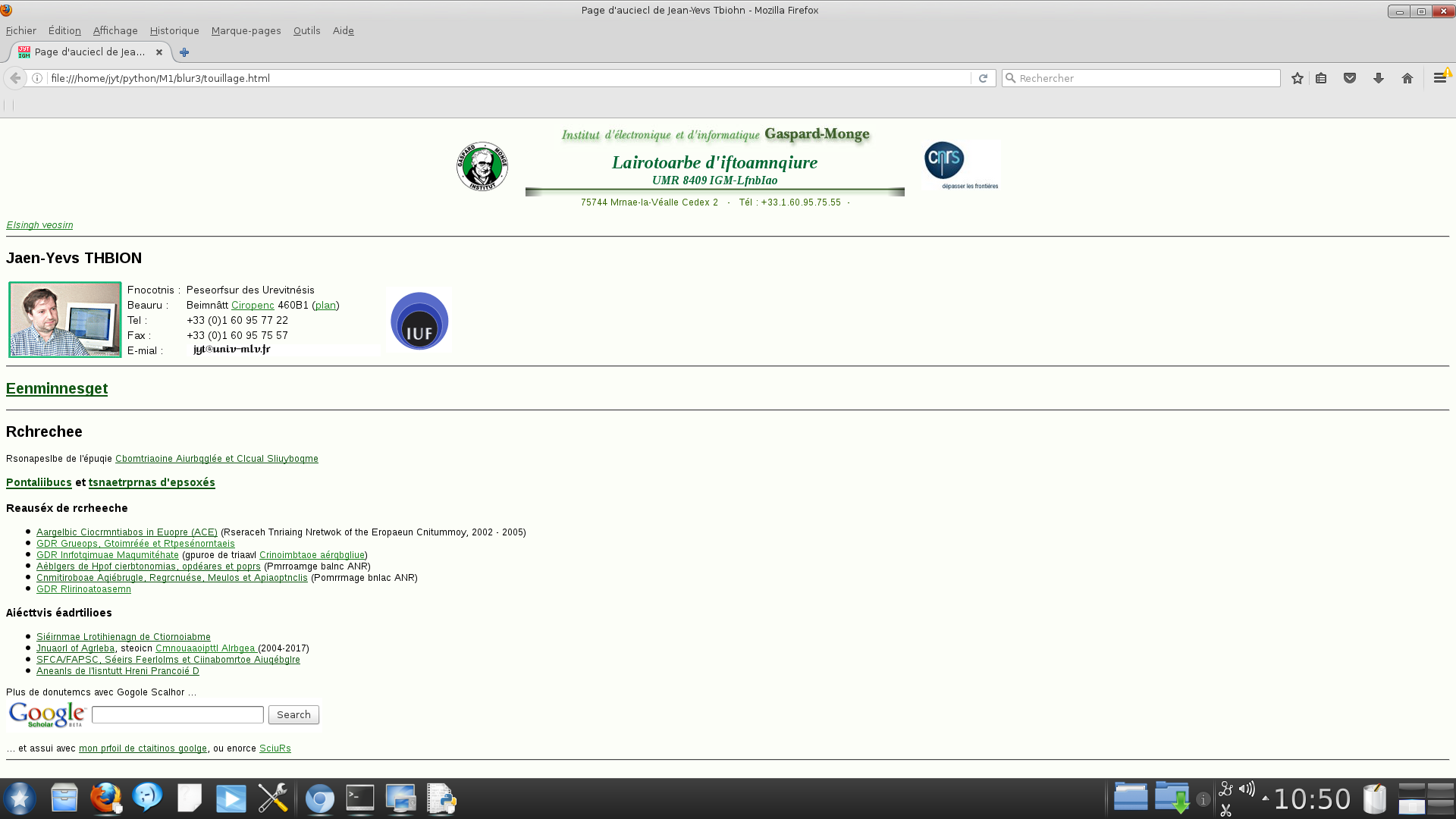
Dans le cours, on utilisera plutôt le touilleur de texte vu en TD pour brouiller une page web sans modifier sa mise en page.
Au passage, voilà la version utilisant une expression régulière :
# module touille.py
import random, re
p = re.compile('(\w)(\w\w+)(\w)', re.M) # mot d'au moins 4 lettres
def touille(m):
milieu = list(m.group(2)) # group(2) est le milieu
random.shuffle(milieu)
return m.group(1) + ''.join(milieu) + m.group(3)
def blurr(s):
return p.sub(touille,s)
from touille import blurr
blurr('Il est plus facile de se laver les dents dans un verre à pied que de se laver les pieds dans un verre à dents.')
'Il est plus flacie de se laevr les dnets dans un verre à pied que de se lvear les pdies dans un vrree à dnets.'
Pour d'autres exemples, voir ce site.
Exemple: Elmer Fudd cf. Bugs Bunny)
Les dialectes sont définis par des substitutions,
attribut subs d'une sous-classe Dialectizer
de BaseHTMLProcessor, elle même dérivée de HTMLParser.
class FuddDialectizer(Dialectizer):
"""convert HTML to Elmer Fudd-speak"""
subs = ((r'[rl]', r'w'),
(r'qu', r'qw'),
(r'th\b', r'f'),
(r'th', r'd'),
(r'n[.]', r'n, uh-hah-hah-hah.'))
Elle réalise l'analyse syntaxique du HTML.
Dès qu'un élément utile est identifié (une balise ouvrante,
start_tag, par exemple),
une méthode handle_starttag, do_tag, ... est appelée.
HTMLParser analyse le HTML en 8 types de données, et appelle une méthode différente pour chaque cas :
Pour l'utiliser, il faut créer une classe dérivée de HTMLParser, et surcharger ces 8 méthodes.
from html.parser import HTMLParser
class MyHTMLParser(HTMLParser):
def handle_starttag(self, tag, attrs):
print ("Balise ouvrante :", tag, attrs)
def handle_endtag(self, tag):
print ("Balise fermante :", tag)
def handle_data(self, data):
print ("Texte :", repr(data))
# On créee une instance
parser = MyHTMLParser()
# Et on lui donne à manger
from urllib.request import urlopen
s = urlopen('http://igm.univ-mlv.fr/~jyt/M1_python/').read().decode('utf8')
parser.feed(s)
Balise ouvrante : html []
Texte : '\n\t'
Balise ouvrante : body []
Texte : '\n\t\t'
Balise ouvrante : h1 []
Texte : ' M1 Informatique : Python '
Balise fermante : h1
Texte : '\n\t\t'
Balise ouvrante : ul []
Texte : '\n\t\t\t'
Balise ouvrante : li []
Texte : ' Commencer ici : '
Balise ouvrante : a [('href', 'http://www.python.org/')]
Texte : 'python.org'
Balise fermante : a
Texte : '\n\t\t\t'
Balise ouvrante : li []
Texte : ' La '
Balise ouvrante : a [('href', 'http://docs.python.org/3.8')]
Texte : 'documentation'
Balise fermante : a
Texte : ' officielle\n\t\t\t'
Balise ouvrante : li []
Texte : ' Le '
Balise ouvrante : a [('href', 'http://www.pythonchallenge.com/')]
Texte : ' Python Challenge'
Balise fermante : a
Texte : '\n\t\t\t'
Balise ouvrante : li []
Texte : ' '
Balise ouvrante : a [('href', 'https://python.developpez.com/cours/DiveIntoPython/')]
Balise ouvrante : i []
Texte : 'Dive into Python'
Balise fermante : i
Balise fermante : a
Texte : ' \n\t\t\tpar '
Balise ouvrante : a [('href', 'http://en.wikipedia.org/wiki/Mark_Pilgrim_%28software_developer%29')]
Texte : 'Mark Pilgrim'
Balise fermante : a
Texte : ' \n\t\t\t(un livre recommandé mais ancien);\n\t\t\t'
Balise ouvrante : a [('href', 'http://diveintopython3.problemsolving.io/')]
Texte : 'version Python 3'
Balise fermante : a
Texte : '. \n\t\t\t'
Balise ouvrante : li []
Texte : ' La '
Balise ouvrante : a [('href', 'http://fr.wikipedia.org/wiki/Python_%28langage%29')]
Texte : 'page'
Balise fermante : a
Texte : ' de Wikipédia contient un bon résumé\n\t\t\t'
Balise ouvrante : li []
Texte : ' Introduction au '
Balise ouvrante : i []
Texte : 'notebook'
Balise fermante : i
Texte : ' ipython ou jupyter :)\n\t\t\t'
Balise ouvrante : ul []
Texte : ' \n\t\t\t\t'
Balise ouvrante : li []
Texte : ' '
Balise ouvrante : a [('href', 'intro_jupyter.html')]
Texte : 'Exemple'
Balise fermante : a
Texte : " de ce qu'on peut obtenir (converti en html)\n\t\t\t\t"
Balise ouvrante : li []
Texte : ' Le '
Balise ouvrante : a [('href', 'intro_jupyter.ipynb')]
Texte : 'code source'
Balise fermante : a
Texte : ' (fichier '
Balise ouvrante : tt []
Texte : '.ipynb'
Balise fermante : tt
Texte : '), à télécharger\n\t\t\t\t'
Balise ouvrante : li []
Texte : ' Lancer un terminal, aller dans le dossier contenant le fichier '
Balise ouvrante : tt []
Texte : '.ipynb'
Balise fermante : tt
Texte : ', et entrer la commande '
Balise ouvrante : tt []
Texte : 'jupyter notebook'
Balise fermante : tt
Texte : '\n\t\t\t'
Balise fermante : ul
Texte : '\n\t\t\t'
Balise ouvrante : li []
Texte : ' Cours 1 (22/9/21) '
Balise ouvrante : a [('href', 'python3_M1_2021-1.html')]
Texte : 'html'
Balise fermante : a
Texte : ' - '
Balise ouvrante : a [('href', 'python3_M1_2021-1.ipynb')]
Texte : 'notebook'
Balise fermante : a
Texte : '\n\t\t\t'
Balise ouvrante : li []
Texte : ' '
Balise ouvrante : a [('href', 'td1_python3_2020.html')]
Texte : ' TD 1'
Balise fermante : a
Texte : ' (22/9/21)\n\t\t\t'
Balise ouvrante : li []
Texte : ' '
Balise ouvrante : a [('href', 'script3.py')]
Texte : 'modèle de script'
Balise fermante : a
Texte : ' avec options et documentation\n\t\t\t'
Balise ouvrante : li []
Texte : ' '
Balise ouvrante : a [('href', 'td1_sol_3_2021.html')]
Texte : 'Corrigé'
Balise fermante : a
Texte : ' du TD 1\n\t\t\t'
Balise ouvrante : li []
Texte : ' Cours 2 (29/09/2021) '
Balise ouvrante : a [('href', 'Python3_M1_2021-2.html')]
Texte : 'html'
Balise fermante : a
Texte : ' - '
Balise ouvrante : a [('href', 'Python3_M1_2021-2.ipynb')]
Texte : 'notebook'
Balise fermante : a
Texte : '\n\t\t\t'
Balise ouvrante : li []
Texte : ' '
Balise ouvrante : a [('href', 'td2_2021_texte.html')]
Texte : 'TD 2'
Balise fermante : a
Texte : ' (29/09/2021)\n\t\t\t'
Balise ouvrante : li []
Texte : ' '
Balise ouvrante : a [('href', 'td2_solpy3_2021.html')]
Texte : 'Corrigé'
Balise fermante : a
Texte : ' du TD 2\n\t\t\t'
Balise ouvrante : li []
Texte : ' Cours 3 (6/10/2021) '
Balise ouvrante : a [('href', 'python3_M1_2021-3.html')]
Texte : 'html'
Balise fermante : a
Texte : ' - '
Balise ouvrante : a [('href', 'python3_M1_2021-3.ipynb')]
Texte : 'notebook'
Balise fermante : a
Texte : '\n\t\t\t'
Balise ouvrante : li []
Texte : ' '
Balise ouvrante : a [('href', 'td3_2021_texte.html')]
Texte : 'TD 3'
Balise fermante : a
Texte : ' (6/10/2021)\n\n\n\n\t\t\n\n\n\t\t\t\n\n\t\t'
Balise fermante : ul
Texte : '\n\t'
Balise fermante : body
Texte : '\n'
Balise fermante : html
Texte : '\n\n\t\t\n'
But : une classe pour extraire les liens d'une page web.
from html.parser import HTMLParser
class URLLister(HTMLParser):
def reset(self):
HTMLParser.reset(self)
self.urls = []
def handle_starttag(self, tag, attrs):
href = [v for k, v in attrs if k=='href'] # attrs est une liste de couples
if href:
self.urls.extend(href)
s = urlopen('http://igm.univ-mlv.fr/~jyt/M1_python').read().decode('utf8')
p = URLLister()
p.feed(s)
p.close()
for u in p.urls: print (u)
http://www.python.org/ http://docs.python.org/3.8 http://www.pythonchallenge.com/ https://python.developpez.com/cours/DiveIntoPython/ http://en.wikipedia.org/wiki/Mark_Pilgrim_%28software_developer%29 http://diveintopython3.problemsolving.io/ http://fr.wikipedia.org/wiki/Python_%28langage%29 intro_jupyter.html intro_jupyter.ipynb python3_M1_2021-1.html python3_M1_2021-1.ipynb td1_python3_2020.html script3.py td1_sol_3_2021.html Python3_M1_2021-2.html Python3_M1_2021-2.ipynb td2_2021_texte.html td2_solpy3_2021.html python3_M1_2021-3.html python3_M1_2021-3.ipynb td3_2021_texte.html
En appliquant ceci à la page du cours, on pourrait tester (avec une regexp) si un nouveau pdf a été mis en ligne et le récuperer automatiquement ...
Il s'agit de reproduire à l'identique le document HTML, en traduisant seulement le texte, sauf s'il est encadré par une balise <pre> (on ne traduirait pas un programme).
Pour varier les plaisirs, on pourra traduire de l'anglais en texan :
(^|" ")"American" changeCase(" Amerkin");
(^|" ")"California" changeCase(" Caleyfornyuh");
(^|" ")"Dallas" changeCase(" Big D.");
(^|" ")"Fort Worth" changeCase(" Fowert Wurth");
(^|" ")"Houston" changeCase(" Useton");
(^|" ")"I don't know" changeCase(" I-O-no");
(^|" ")"I will"|" I'll" changeCase(" Ahl");
...
On commence par construire une classe dérivée qui ne fait rien : elle recompose la page analysée sans la modifier.
On surchargera ensuite la méthode handle_data pour modifier le texte à notre convenance.
from html.entities import entitydefs
class BaseHTMLProcessor(HTMLParser):
def reset(self):
self.pieces = []
HTMLParser.reset(self)
def handle_starttag(self, tag, attrs):
strattrs = "".join([' %s="%s"' % (key, value)
for key, value in attrs])
self.pieces.append("<%(tag)s%(strattrs)s>" % locals())
def handle_endtag(self, tag):
self.pieces.append("</%(tag)s>" % locals())
def handle_charref(self, ref):
self.pieces.append("&#%(ref)s;" % locals())
def handle_entityref(self, ref):
self.pieces.append("&%(ref)s" % locals())
if htmlentitydefs.entitydefs.has_key(ref):
self.pieces.append(";")
def handle_data(self, text): # A surcharger
self.pieces.append(text)
def handle_comment(self, text):
self.pieces.append("<!--%(text)s-->" % locals())
def handle_pi(self, text):
self.pieces.append("<?%(text)s>" % locals())
def handle_decl(self, text):
self.pieces.append("<!%(text)s>" % locals())
def output(self):
"""Return processed HTML as a single string"""
return "".join(self.pieces)
b = BaseHTMLProcessor()
b.feed(s)
b.close()
print (b.pieces)
['<html>', '\n\t', '<body>', '\n\t\t', '<h1>', ' M1 Informatique : Python ', '</h1>', '\n\t\t', '<ul>', '\n\t\t\t', '<li>', ' Commencer ici : ', '<a href="http://www.python.org/">', 'python.org', '</a>', '\n\t\t\t', '<li>', ' La ', '<a href="http://docs.python.org/3.8">', 'documentation', '</a>', ' officielle\n\t\t\t', '<li>', ' Le ', '<a href="http://www.pythonchallenge.com/">', ' Python Challenge', '</a>', '\n\t\t\t', '<li>', ' ', '<a href="https://python.developpez.com/cours/DiveIntoPython/">', '<i>', 'Dive into Python', '</i>', '</a>', ' \n\t\t\tpar ', '<a href="http://en.wikipedia.org/wiki/Mark_Pilgrim_%28software_developer%29">', 'Mark Pilgrim', '</a>', ' \n\t\t\t(un livre recommandé mais ancien);\n\t\t\t', '<a href="http://diveintopython3.problemsolving.io/">', 'version Python 3', '</a>', '. \n\t\t\t', '<li>', ' La ', '<a href="http://fr.wikipedia.org/wiki/Python_%28langage%29">', 'page', '</a>', ' de Wikipédia contient un bon résumé\n\t\t\t', '<li>', ' Introduction au ', '<i>', 'notebook', '</i>', ' ipython ou jupyter :)\n\t\t\t', '<ul>', ' \n\t\t\t\t', '<li>', ' ', '<a href="intro_jupyter.html">', 'Exemple', '</a>', " de ce qu'on peut obtenir (converti en html)\n\t\t\t\t", '<li>', ' Le ', '<a href="intro_jupyter.ipynb">', 'code source', '</a>', ' (fichier ', '<tt>', '.ipynb', '</tt>', '), à télécharger\n\t\t\t\t', '<li>', ' Lancer un terminal, aller dans le dossier contenant le fichier ', '<tt>', '.ipynb', '</tt>', ', et entrer la commande ', '<tt>', 'jupyter notebook', '</tt>', '\n\t\t\t', '</ul>', '\n\t\t\t', '<li>', ' Cours 1 (22/9/21) ', '<a href="python3_M1_2021-1.html">', 'html', '</a>', ' - ', '<a href="python3_M1_2021-1.ipynb">', 'notebook', '</a>', '\n\t\t\t', '<li>', ' ', '<a href="td1_python3_2020.html">', ' TD 1', '</a>', ' (22/9/21)\n\t\t\t', '<li>', ' ', '<a href="script3.py">', 'modèle de script', '</a>', ' avec options et documentation\n\t\t\t', '<li>', ' ', '<a href="td1_sol_3_2021.html">', 'Corrigé', '</a>', ' du TD 1\n\t\t\t', '<li>', ' Cours 2 (29/09/2021) ', '<a href="Python3_M1_2021-2.html">', 'html', '</a>', ' - ', '<a href="Python3_M1_2021-2.ipynb">', 'notebook', '</a>', '\n\t\t\t', '<li>', ' ', '<a href="td2_2021_texte.html">', 'TD 2', '</a>', ' (29/09/2021)\n\t\t\t', '<li>', ' ', '<a href="td2_solpy3_2021.html">', 'Corrigé', '</a>', ' du TD 2\n\t\t\t', '<li>', ' Cours 3 (6/10/2021) ', '<a href="python3_M1_2021-3.html">', 'html', '</a>', ' - ', '<a href="python3_M1_2021-3.ipynb">', 'notebook', '</a>', '\n\t\t\t', '<li>', ' ', '<a href="td3_2021_texte.html">', 'TD 3', '</a>', ' (6/10/2021)\n\n\n\n\t\t\n\n\n\t\t\t\n\n\t\t', '</ul>', '\n\t', '</body>', '\n', '</html>', '\n\n\t\t\n']
b.output()
'<html>\n\t<body>\n\t\t<h1> M1 Informatique : Python </h1>\n\t\t<ul>\n\t\t\t<li> Commencer ici : <a href="http://www.python.org/">python.org</a>\n\t\t\t<li> La <a href="http://docs.python.org/3.8">documentation</a> officielle\n\t\t\t<li> Le <a href="http://www.pythonchallenge.com/"> Python Challenge</a>\n\t\t\t<li> <a href="https://python.developpez.com/cours/DiveIntoPython/"><i>Dive into Python</i></a> \n\t\t\tpar <a href="http://en.wikipedia.org/wiki/Mark_Pilgrim_%28software_developer%29">Mark Pilgrim</a> \n\t\t\t(un livre recommandé mais ancien);\n\t\t\t<a href="http://diveintopython3.problemsolving.io/">version Python 3</a>. \n\t\t\t<li> La <a href="http://fr.wikipedia.org/wiki/Python_%28langage%29">page</a> de Wikipédia contient un bon résumé\n\t\t\t<li> Introduction au <i>notebook</i> ipython ou jupyter :)\n\t\t\t<ul> \n\t\t\t\t<li> <a href="intro_jupyter.html">Exemple</a> de ce qu\'on peut obtenir (converti en html)\n\t\t\t\t<li> Le <a href="intro_jupyter.ipynb">code source</a> (fichier <tt>.ipynb</tt>), à télécharger\n\t\t\t\t<li> Lancer un terminal, aller dans le dossier contenant le fichier <tt>.ipynb</tt>, et entrer la commande <tt>jupyter notebook</tt>\n\t\t\t</ul>\n\t\t\t<li> Cours 1 (22/9/21) <a href="python3_M1_2021-1.html">html</a> - <a href="python3_M1_2021-1.ipynb">notebook</a>\n\t\t\t<li> <a href="td1_python3_2020.html"> TD 1</a> (22/9/21)\n\t\t\t<li> <a href="script3.py">modèle de script</a> avec options et documentation\n\t\t\t<li> <a href="td1_sol_3_2021.html">Corrigé</a> du TD 1\n\t\t\t<li> Cours 2 (29/09/2021) <a href="Python3_M1_2021-2.html">html</a> - <a href="Python3_M1_2021-2.ipynb">notebook</a>\n\t\t\t<li> <a href="td2_2021_texte.html">TD 2</a> (29/09/2021)\n\t\t\t<li> <a href="td2_solpy3_2021.html">Corrigé</a> du TD 2\n\t\t\t<li> Cours 3 (6/10/2021) <a href="python3_M1_2021-3.html">html</a> - <a href="python3_M1_2021-3.ipynb">notebook</a>\n\t\t\t<li> <a href="td3_2021_texte.html">TD 3</a> (6/10/2021)\n\n\n\n\t\t\n\n\n\t\t\t\n\n\t\t</ul>\n\t</body>\n</html>\n\n\t\t\n'
Ce code utilise quelques astuces typiquement pythonesques.
locals() et globals() renvoient des dictionnaires de variables locales et globales ...
def f(x):
y = 'toto'
print (locals())
f(42)
{'x': 42, 'y': 'toto'}
Si on venait de lancer l'interpréteur, on aurait
>>> print (globals())
{'f': <function f at 0x402d35a4>, '__builtins__':
<module '__builtin__' (built-in)>, '__name__': '__main__',
'__doc__': None}
>>> dir()
['__builtins__', '__doc__', '__name__', 'f']
Mais dans un notebook jupyter, on en a beaucoup trop pour pouvoir les afficher ...
Les lignes
if __name__ == "__main__":
for k, v in globals().items():
print (k, "=", v)
ajoutées à la fin du fichier BaseHTMLProcessor.py décrit dans le livre produiraient l'effet suivant, quand le programme est lancé en ligne de commande :
$ python BaseHTMLProcessor.py
__copyright__ = Copyright (c) 2001 Mark Pilgrim
HTMLParser = HTMLParser.HTMLParser
__license__ = Python
__builtins__ = <module '__builtin__' (built-in)>
__file__ = BaseHTMLProcessor.py [ ... snip ...]
Rappel : formatage par dictionnaire
d = {'animal':'cheval', 'parent':'cousin', 'aliment':'foin', 'jour':'dimanche'}
s = 'Le %(animal)s de mon %(parent)s ne mange du %(aliment)s que le %(jour)s'
s % d
'Le cheval de mon cousin ne mange du foin que le dimanche'
On peut donc utiliser locals() pour remettre
en place les attributs des balises sans avoir à les connaître :
def handle_starttag(self, tag, attrs):
strattrs = "".join([' %s="%s"' % (key, value)
for key, value in attrs])
self.pieces.append("<%(tag)s%(strattrs)s>" % locals())
C'est ce procédé qui permet de reconstituer (essentiellement) le HTML qu'on ne souhaite pas modifier.
Pourquoi essentiellement ? A cause des "guillemets":
htmlSource = """
<html>
<head>
<title>Test page</title>
</head>
<body>
<ul>
<li><a href=index.html>Home</a></li>
<li><a href=toc.html>Table of contents</a></li>
<li><a href=history.html>Revision history</a></li>
</body>
</html>"""
parser = BaseHTMLProcessor()
parser.feed(htmlSource)
parser.close()
print (parser.output())
<html>
<head>
<title>Test page</title>
</head>
<body>
<ul>
<li><a href="index.html">Home</a></li>
<li><a href="toc.html">Table of contents</a></li>
<li><a href="history.html">Revision history</a></li>
</body>
</html>
On construit ensuite une classe Dialectizer qui dérive de BaseHTMLProcessor. Son rôle est de "traduire" le texte de la page, sauf lorsqu'il doit être rendu verbatim (<pre>...</pre>).
Il lui faudra donc un attribut verbatim qui permet de savoir si l'on doit traduire ou pas :
Ceci étant acquis, on peut maintenant surcharger handle_data :
def handle_data(self, text):
self.pieces.append(self.verbatim
and text
or self.process(text))
La méthode process dépendra de la traduction désirée.
On remarquera l'usa ge astucieux des booléens
>>> (1==1) and 'toto'
'toto'
>>> (1==0) and 'toto'
False
>>> (1==0) or 'toto'
'toto'
>>> (1==0) and 'toto' or 'titi'
'titi'
Explication (attention à l'ordre !) :
>>> 'toto' and (1==1)
True
>>> 'toto' and (1==0)
False
>>>
La sémantique est
x or y --> if x is false, then y, else x x and y --> if x is false, then x, else y
# module touille.py
import random, re
p = re.compile('(\w)(\w+)(\w)', re.M)
def touille(m):
milieu = list(m.group(2))
random.shuffle(milieu)
return m.group(1) + ''.join(milieu) + m.group(3)
def blurr(s):
return p.sub(touille,s)
# file newHTMLProcessor.py
"""Base class for creating HTML processing modules
This class is designed to take HTML as input and spit out equivalent
HTML as output. By itself it's not very interesting; you use it by
subclassing it and providing the methods you need to create your HTML
transformation.
Adapted from Mark Pilgrim's book "Dive into Python".
sgmllib.SGMLParser replaced in Python 3 by html.parser.HTMLParser.
"""
from html.parser import HTMLParser
from html.entities import entitydefs
class BaseHTMLProcessor(HTMLParser):
def reset(self):
# extend (called by HTMLParser.__init__)
self.pieces = []
HTMLParser.reset(self)
def handle_starttag(self, tag, attrs):
# called for each start tag
# attrs is a list of (attr, value) tuples
# e.g. for <pre class="screen">, tag="pre", attrs=[("class", "screen")]
# Ideally we would like to reconstruct original tag and attributes, but
# we may end up quoting attribute values that weren't quoted in the source
# document, or we may change the type of quotes around the attribute value
# (single to double quotes).
# Note that improperly embedded non-HTML code (like client-side Javascript)
# may be parsed incorrectly by the ancestor, causing runtime script errors.
# All non-HTML code must be enclosed in HTML comment tags (<!-- code -->)
# to ensure that it will pass through this parser unaltered (in handle_comment).
strattrs = "".join([' %s="%s"' % (key, value) for key, value in attrs])
self.pieces.append("<%(tag)s%(strattrs)s>" % locals())
def handle_endtag(self, tag):
# called for each end tag, e.g. for </pre>, tag will be "pre"
# Reconstruct the original end tag.
self.pieces.append("</%(tag)s>" % locals())
def handle_charref(self, ref):
# called for each character reference, e.g. for " ", ref will be "160"
# Reconstruct the original character reference.
self.pieces.append("&#%(ref)s;" % locals())
def handle_entityref(self, ref):
# called for each entity reference, e.g. for "©", ref will be "copy"
# Reconstruct the original entity reference.
self.pieces.append("&%(ref)s" % locals())
# standard HTML entities are closed with a semicolon; other entities are not
if htmlentitydefs.entitydefs.has_key(ref):
self.pieces.append(";")
def handle_data(self, text):
# called for each block of plain text, i.e. outside of any tag and
# not containing any character or entity references
# Store the original text verbatim.
self.pieces.append(text)
def handle_comment(self, text):
# called for each HTML comment, e.g. <!-- insert Javascript code here -->
# Reconstruct the original comment.
# It is especially important that the source document enclose client-side
# code (like Javascript) within comments so it can pass through this
# processor undisturbed; see comments in unknown_starttag for details.
self.pieces.append("<!--%(text)s-->" % locals())
def handle_pi(self, text):
# called for each processing instruction, e.g. <?instruction>
# Reconstruct original processing instruction.
self.pieces.append("<?%(text)s>" % locals())
def handle_decl(self, text):
# called for the DOCTYPE, if present, e.g.
# <!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"
# "http://www.w3.org/TR/html4/loose.dtd">
# Reconstruct original DOCTYPE
self.pieces.append("<!%(text)s>" % locals())
def output(self):
"""Return processed HTML as a single string"""
return "".join(self.pieces)
if __name__ == "__main__":
for k, v in globals().items():
print (k, "=", v)
#!/usr/bin/env python
"""Web page blurrer for Python
This program is adapted from "Dive Into Python", a free Python book for
experienced programmers. Visit http://diveintopython.org/ for the
latest version.
New version using Python 3, html.parser and including images.
"""
__author__ = "Mark Pilgrim (mark@diveintopython.org)"
__updated_by__ = "Jean-Yves Thibon"
__version__ = "$Revision: 3.0 $"
__date__ = "$Date: 2019/10/07 $"
__copyright__ = "Copyright (c) 2001 Mark Pilgrim"
__license__ = "Python"
import re
from newHTMLProcessor import BaseHTMLProcessor
from touille import blurr
import codecs
from urllib.parse import urljoin
class Dialectizer(BaseHTMLProcessor):
subs = ()
def __init__(self,root_url=None):# ajout
BaseHTMLProcessor.__init__(self)
self.url = root_url
def __compl(self, x):# pair (key, value)
if x[0] == 'href' or x[0] == 'src':
return (x[0], urljoin(self.url,x[1]))
else: return x
def reset(self):
# extend (called from __init__ in ancestor)
# Reset all data attributes
self.verbatim = 0
BaseHTMLProcessor.reset(self)
def handle_starttag(self,tag,args):
if self.url:
args = [self.__compl(x) for x in args]
if tag in ["pre","script","style"]: self.verbatim += 1
strattrs = "".join([' %s="%s"' % (key, value) for key, value in args])
self.pieces.append("<%(tag)s%(strattrs)s>" % locals())
def handle_endtag(self,tag):
# called for every </pre> tag in HTML source
# Decrement verbatim mode count
if tag in ["pre","script","style"]: self.verbatim -= 1
self.pieces.append("</%(tag)s>" % locals())
def handle_data(self, text):
# override
# called for every block of text in HTML source
# If in verbatim mode, save text unaltered;
# otherwise process the text with a series of substitutions
self.pieces.append(self.verbatim and text or self.process(text))
def process(self, text):
# called from handle_data
text = blurr(text)
return text
def translate(url):
"""fetch URL and blurr"""
from urllib.request import urlopen
sock = urlopen(url)
htmlSource = sock.read()
sock.close()
s = htmlSource.decode('utf-8')
parser = Dialectizer(url)#test
parser.feed(s)
parser.close()
return parser.output()
def test(url):
"""test against URL"""
outfile = "touillage.html"
fsock = codecs.open(outfile, "wb",encoding='UTF-8')
fsock.write(translate(url))
fsock.close()
import webbrowser
K = webbrowser.Mozilla('firefox')
webbrowser.register('firefox', None, K)
K.open_new(outfile)
if __name__ == "__main__":
s = test("http://igm.univ-mlv.fr/~jyt/")
Ce code est instructif, mais assez compliqué. On peut faire plus simple avec BeautifulSoup.