Le PL/PGSQL
Avantages du PL/PGSQL
Le PL/PGSQL présente un certains nombre d'avantages qui peuvent justifier le choix de son utilisation dans le cadre d'une application nécessitant un SGBD.
Il s'agit d'un language simple et relativement rapide à apprendre, car très proche du SQL. De plus il est très proche du PL/SQL d'Oracle, et de nombreuses indications dans la documentation officielle permettent de rendre les procédures stockées compatibles avec les 2 SGBD, ou du moins de les adapter facilement.
Accroissement des performances
Le fait d'utiliser ce langage SQL évolué permet de réduire les requetes inter-serveur:
le SQL standard implique en général d'avoir une partie de traitement des données dans le serveur d'application. Une requete va ainsi etre effectuée vers le SGBD, puis le resultat va donner lieu à un traitement sur le serveur d'application, puis le resultat de ce traitement va ensuite donner lieu à d'autres requetes dont les résultats seront de nouveau traitées par le serveur d'application, etc...
Il peut ainsi s'ensuivre un grand nombre d'echanges entre les deux serveurs.

Le shéma ci dessus montre un exemple simple où les requetes clientes pourraient bien évidement être remplacées par une requetes plus complexes.... mais ce n'est qu'un exemple! ;)
Un autre exemple peut être plus pertinent et celui d'une mise à jour d'un ensemble d'enregistrements: dans le cas de requetes clientes, une boucle sur le serveur d'application enverra une succession de requetes d'updates (et éventuelement d'autres requetes..) pour chacun des renregistrements. Le nombre de requetes inter-serveur dependra ainsi du nombre d'enregistrements à mettre à jour.
Le PL/PGSL permettrait alors de faire appel à une fonction unique, en passant les identifiants des enregistrements en arguments. La boucle et les eventuelles autres requetes seraient alors traitées dans le SGBD, et ce gràce à une seule requete inter-serveur, quelque soit le nombre d'enregistrements.
Dans le cadre de serveurs applicatifs et de SGBD distants, le gain de performance du à cette diminution d'échanges est alors non négligeable et conséquent.
De plus, appeler une fonction avec des arguments provoque une utilisation du réseau nettement moins importante que de transmettre la totalité d'une requete, il suffit de compter le nombre de caractères pour s'en rendre compte....
Le PL/PGSQL présente aussi l'avantage de faire de la répartition de charges:
en effet, comme nous venons de le voire, il est possible de déléguer une partie des traitements habituellement effectués sur le serveur d'application au SGBD.
On peu citer par exemple des calculs de statistiques qui nécessiteraient de faire un grand nombre d'opérations mathématiques sur un grand nombre d'enregistrements (sommes, divisions, moyennes,...).
Faire effectuer ces calculs par le SGBD permet alors de liberer une partie de la charge du serveur d'application en la déléguant au SGBD. Celà prend tout son sens lorsque SGBD et serveur d'application sont sur des machines distinctes. Il est alors possible de faire evoluer les matériels en fonctions des charges des deux serveurs selon leurs utilisations.
La présence des requetes dans le SGBD permet alors à celui-ci d'effectuer différents travaux d'optimisation tels que la précompilation. Ainsi, il est possible de préciser, grace à l'option IMMUTABLE, qu'une fonction retourne toujours les meme resultats avec des arguments identiques.
Ergonomie
Le PL/PGSQL présente d'autre part d'évidents avantages ergonomiques.
Il permet de séparer plus encore les différents éléments du code source: les codes sources du serveur d'application ne contiennent plus les requetes SQL mais seulement des appels de fonction. Le SGBD se voit alors contenir les données et les requetes pour les obtenir. Chacuns des serveurs ont alors des responsabilités beaucoup plus encadrées et plus en rapport avec leur role original: Le serveur d'application présente les donnés, le SGBD les gèrent. On peut assimiler cette séparations des différents éléménts d'une application à celle faite par l'utisation des feuilles de style à l'HTML.
Les modifications des requetes et de la base de données peut alors être déléguée à un spécialiste (administrateur du SGBD) et ne donner lieu à aucune modification des codes sources.
De plus, comme nous l'avons vu dans les exemples précedents, les requetes peuvent etre traitées par blocs beaucoup plus facilement. Au sein d'une meme fonction, on peu appeller un grand nombre de requetes (select, insert, updates,...) en une seule fois, et bien sur mettre en place un système simple et avancé de commit et rollback.
Outre un grand nombre de requetes au sein d'une meme fonction, il est possible d'appeller des fonctions entre elles. Il est alors possible d'écrire un grand nombre de requetes générales appelées ensuite par de nombreuses requetes spécialisées.
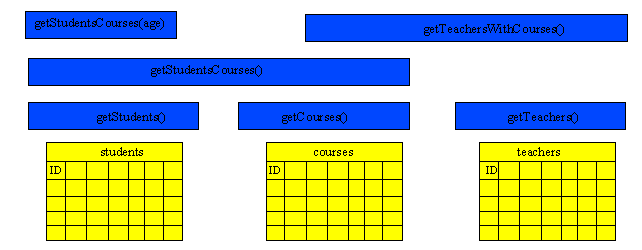
Ainsi, dans cet exemple, on a une fonction pour chacunes des tables students, courses et teachers. En plus d'une simple selection de l'ensemble des tuples des tables, ces fonctions pouraient prendre des parametres de formatage des données des tuples, tels que la mise en majuscule des caractères, ou encore le remplacement de certains caractères.
La fonction getStudentsCourses() fait quand à elle une jointure entre les tables students et courses. Pour cela, elle ne fait pas appel au tables mais aux fonctions. Elle dispose alors des eventuelles options de formatage des données de ces fonctions.
La fonction getStudentsCourses(age) va quand à elle faire appel à cette dernière fonction en ajoutant une simple clause where au résultat de la fonction.
Si les tables venaient à etre modifiées, il n'y aurait alors que 2 fonctions à modifier au lieu de 4 requetes!
De plus, chacunes des fonctions peut donner lieu à des mofifications, pour de l'optimisation par exemple, et ainsi en faire profiter toutes les fonctions qui les appellent.