Entrepot de Donnees
Datawarehouse
C'est le lieu de stockage des données provenant des bases externes servant à l'aide à la décision. C'est dans cette base que les utilisateurs puissent les données par le biais d'outil de restitution.
Structure
Le datawarehouse se structure en quatre classes de données, organisées selon un
axe historique est un axe synthétique.
 Illustration 5: Structure d'un Datawarehouse (source : D Nakache,
Conservatoire National des arts et métiers)
Les données détaillées : Elles reflètent
des évènements les plus récents. Les données provenant
des systèmes de production sont intégrées à ce niveau.
Les données agrégées : Elles correspondent
à des éléments d'analyse représentatifs des besoins
des utilisateurs. Ce sont donc des données déjà traitées
par le système et représentant un premier résultat d'analyse
et de synthèse des données contenues dans les systèmes
de production. Elles doivent être facilement accessibles et compréhensibles.
Les données historisées : Chaque nouvelle insertion dans
le datawarehouse ne détruit pas les anciennes valeurs mais créée
une nouvelle insertion.
Les méta-données : Il s'agit « de données
sur les données ». Elles décrivent les règles
ou processus attachés aux données du système. Les méta-données
permettront notamment de connaître :
Illustration 5: Structure d'un Datawarehouse (source : D Nakache,
Conservatoire National des arts et métiers)
Les données détaillées : Elles reflètent
des évènements les plus récents. Les données provenant
des systèmes de production sont intégrées à ce niveau.
Les données agrégées : Elles correspondent
à des éléments d'analyse représentatifs des besoins
des utilisateurs. Ce sont donc des données déjà traitées
par le système et représentant un premier résultat d'analyse
et de synthèse des données contenues dans les systèmes
de production. Elles doivent être facilement accessibles et compréhensibles.
Les données historisées : Chaque nouvelle insertion dans
le datawarehouse ne détruit pas les anciennes valeurs mais créée
une nouvelle insertion.
Les méta-données : Il s'agit « de données
sur les données ». Elles décrivent les règles
ou processus attachés aux données du système. Les méta-données
permettront notamment de connaître :
- quelles sont les données entreposées, leur format, leur signification, leur degrés d'exactitude.
- les processus de récupération/extraction dans les bases sources.
- la date du dernier chargement du datawarehouse.
- l'historique des données sources et de celles du datawarehouse.
Stockage
Le stockage au sein d'un datawarehouse a un besoin de synthèse (agrégation des
données) et un besoin de détails (conservation des données
détaillées).
Ce stockage peut être réalisé de trois manières différentes
: structure directe simple, structure de cumul simple, par résumé
déroulant.
Structure directe simple: On fait des mises à jour du datawarehouse avec
des laps de temps important.
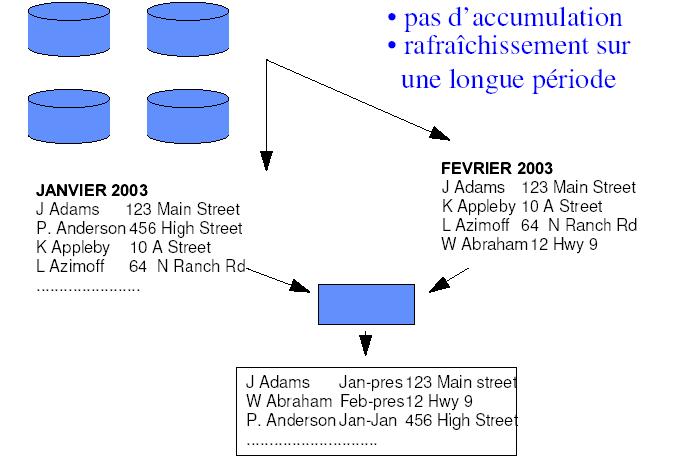 Illustration 7: Strucure directe simple (source : D Donsez,
Université Joseph Fournier)
Structure de cumul simple : on stocke les données de chaque mise à jour,
les mises à jour étant fréquentes (par exemple tous les jours)
on a un espace occupé important, mais on ne perd pas d’information.
Illustration 7: Strucure directe simple (source : D Donsez,
Université Joseph Fournier)
Structure de cumul simple : on stocke les données de chaque mise à jour,
les mises à jour étant fréquentes (par exemple tous les jours)
on a un espace occupé important, mais on ne perd pas d’information.
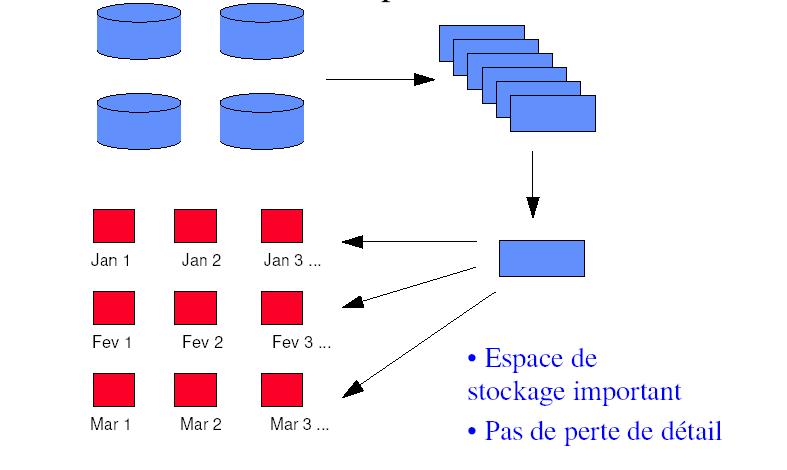 Illustration 8: Structure de cumul simple (source : D Donsez,
Université Joseph Fournier)
Structure par résumé déroulant
: à chaque mise à jour, on stocke des données détaillées,
et on synthétise les anciennes données en fonction de leur age.
Plus une donnée est vieille, moins elle est détaillée.
Illustration 8: Structure de cumul simple (source : D Donsez,
Université Joseph Fournier)
Structure par résumé déroulant
: à chaque mise à jour, on stocke des données détaillées,
et on synthétise les anciennes données en fonction de leur age.
Plus une donnée est vieille, moins elle est détaillée.
 Illustration 9: Strucure par résumé déroulant
(source : D Donsez, Université Joseph Fournier)
Illustration 9: Strucure par résumé déroulant
(source : D Donsez, Université Joseph Fournier)
Modelisation
Afin de comprendre le niveau conceptuel de la modélisation d'un datawarehouse, on va définir
deux concepts : le concept de fait et le concept de dimension.
Concept de fait : Un fait représente un sujet d'analyse. Il est constitué
de plusieurs mesures relatives au sujet traité. Ces mesures sont numériques
et généralement valorisées de façon continue.
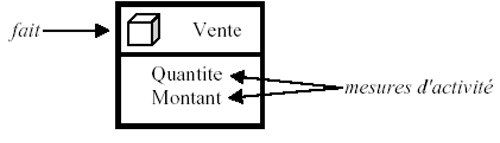 Illustration 10: Table des faits (source : J Detroyes, supinfo)
Concept de dimensions : La dimensions est le critère
suivant lequel on souhaite évaluer, quantifier, qualifier le fait.
Illustration 10: Table des faits (source : J Detroyes, supinfo)
Concept de dimensions : La dimensions est le critère
suivant lequel on souhaite évaluer, quantifier, qualifier le fait.
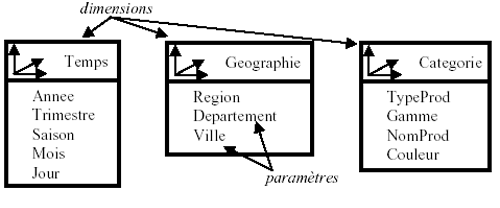 Illustration 11: Dimension (source : J Detroyes, supinfo)
On part du principe que les données sont des faits à analyser selon plusieurs dimensions.
Il est ainsi possible de réaliser une structure de données simple
qui correspond à ce besoin de modélisation multidimensionnelle.
Cette structure est constituée du fait central et des dimensions.
Au niveau logique cela peut se traduire par trois modèles différents : en étoile,
en flocon de neige ou en constellation.
Modèle en étoile : Le centre est la table des faits, et les branches
en sont les dimensions. Pour une dimension il existe plusieurs faits. La structure
est dissymétrique : la table des faits est énorme et les tables
des dimensions sont petites. Les faits sont généralement numériques
alors que les dimensions sont qualitatives.
Illustration 11: Dimension (source : J Detroyes, supinfo)
On part du principe que les données sont des faits à analyser selon plusieurs dimensions.
Il est ainsi possible de réaliser une structure de données simple
qui correspond à ce besoin de modélisation multidimensionnelle.
Cette structure est constituée du fait central et des dimensions.
Au niveau logique cela peut se traduire par trois modèles différents : en étoile,
en flocon de neige ou en constellation.
Modèle en étoile : Le centre est la table des faits, et les branches
en sont les dimensions. Pour une dimension il existe plusieurs faits. La structure
est dissymétrique : la table des faits est énorme et les tables
des dimensions sont petites. Les faits sont généralement numériques
alors que les dimensions sont qualitatives.
 Illustration 12: Modèle en étoile (source : J
Detroyes, supinfo)
Modèle en flocon: Le principe est le même que pour le modèle
en étoile, mais en plus les dimensions sont décomposées.
Le but est d'économiser ainsi de la place. Cela permet également
d'instaurer une hiérarchie au sein des dimensions. Cela engendre par contre une complexification du modèle.
Illustration 12: Modèle en étoile (source : J
Detroyes, supinfo)
Modèle en flocon: Le principe est le même que pour le modèle
en étoile, mais en plus les dimensions sont décomposées.
Le but est d'économiser ainsi de la place. Cela permet également
d'instaurer une hiérarchie au sein des dimensions. Cela engendre par contre une complexification du modèle.
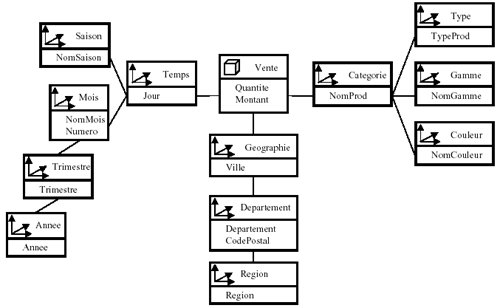 Illustration 13: Modèle en flocon (source : J Detroyes,
supinfo)
Modèle en constellation : Il est encore basé sur
le modèle en étoile. Mais on rassemble plusieurs tables des faits
qui utilisent sur les mêmes dimensions.
Illustration 13: Modèle en flocon (source : J Detroyes,
supinfo)
Modèle en constellation : Il est encore basé sur
le modèle en étoile. Mais on rassemble plusieurs tables des faits
qui utilisent sur les mêmes dimensions.
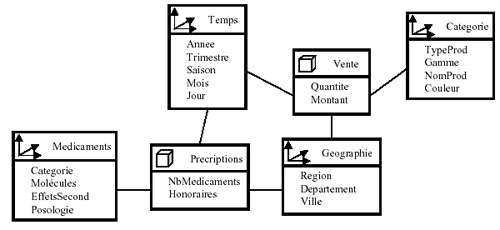 Illustration 14: Modèle en constellation (source : J
Detroyes, supinfo)
Illustration 14: Modèle en constellation (source : J
Detroyes, supinfo)