Les services vocaux par Fabien SCAGNELLI
La reconnaissance vocale
Les différents types de reconnaissance vocale
Pour utiliser les services vocaux, on utilise souvent de la reconnaissance vocale. La reconnaissance vocale est une science faite de statistiques, qui utilise le traitement des signaux sonores pour les comparer avec des sons de références contenus dans une grammaire, et trouver celui qui se rapproche le plus du son d'origine. Si le son d'origine ne se rapproche d'aucun des sons de référence, on dit que le résultat de la reconnaissance vocale est un rejet.
Les mots isolés
On distingue plusieurs types de reconnaissance vocale. Il y a la reconnaissance vocale de mot isolé. Un seul mot doit être prononcé.

Les mots enrobés
Dans ce cas, on autorise l'utilisateur à prononcer un phrase, mais seul certains mot-clés seront compris par le système.

Le langage pseudo-naturel
Ici, l'utilisateur peut prononcer une phrase entière, mais elle ne sera pas comprise entièrement par le système. Seules certaines structures de phrase simples peuvent être analysées.

Le langage naturel
Dans ce dernier cas, c'est la phrase entière qui est comprise. Le temps de la phrase, les tournures grammaticales peuvent être analysés, pour une comprehension optimale.

La reconnaissance des mots
Pour reconnaitre les mots, le signal sonore est comparé à une liste de mots dictés phonétiquement. Grâce a des probabilités, et des scores de similitude attribués a chaque mot, on peut retrouver le ou l'ensemble de mot qui correspondent au mieux au signal sonore.
Lorsque l'on ne veut reconnaitre qu'un seul mot, et que le résultat de la reconnaissance en renvoie plusieurs, il faut faire une étape de désembiguisation. Cela consiste à faire choisir à l'utilisateur quel mot il voulait dire parmis la liste de mots.
Le fichier qui contient l'ensemble de tout les mots reconnaissables par le service s'appelle une grammaire vocale.
Pour reconnaitre les mots, plusieurs algorithmes sont applicables :
- La distance d'édition (on compte le nombre d'opérations minimum à appliquer pour aller d'un motif A à un motif B)
- Les réseaux neuronaux
- Les modèles de Markov à états chachés (Hidden Markov Model)
La reconnaissance du langage naturel
La grammaire vocale
Pour le langage naturel, la grammaire vocale ne contient pas qu'une liste de mots, mais aussi les constructions grammaticales propre à la langue. On y trouve pour chaque mot, la probabilité des mots qui peuvent le suivre. On appelle ce fichier un bigram.
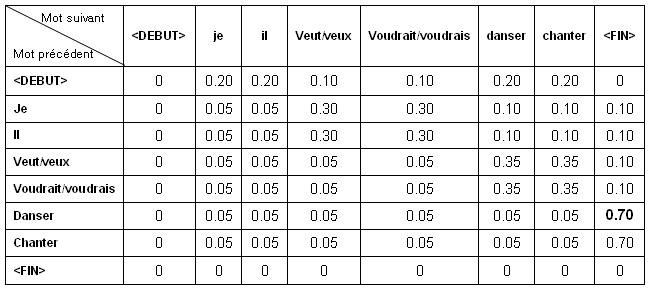
Ce fichier est créé à partir d'une liste de phrase les plus fréquemment cités dans le contexte du service. On appelle cette liste un corpus.
Ainsi, la reconnaissance vocale peut nous retourner les résultats suivants : "je voudrais danser", "il veut chanter", ou bien juste le mot "chanter". Le système peut aussi renvoyer (mais dans des probabilités beaucoup moins élevées) des phrases du type : "veux je il chanter voudrait".
L'analyse syntaxique
Lorsque l'on fait du langage naturel ou pseudo-naturel, un analyse syntaxique est nécessaire pour comprendre ce que veux la personne. On transforme la phrase détectée par la reconnaissance vocale en des mots de commande interprétables par le service.
En réalité, le système détecte différents mots principaux selon des fichiers de règles, tels que les noms de villes ou divers adverbes. Ainsi, plusieurs phrases peuvent donner le même résultat de commande.
Voici quelques exemples si l'on est le lundi 1er janvier 2007 :
- "La météo de demain à Paris"
- "Pour Paris, quel sera le temps du 2 janvier 2007"
- "Est-ce que mardi le temps de Paris sera clément"
L'analyse syntaxique se fait en deux étapes. Tout d'abord, on tague les mots importants, c'est-à-dire que l'on rajoute un signe particulier à ces mots, pour les distinguer. Par exemple, on fait précéder tous les noms de villes par "V_", et tous les noms représentant la météo par "M_". Cela ce fait grâce à des fichiers de correspondances.
Paris => V_Paris
Nice => V_Nice
Brest => V_Brest
Météo => M_Météo
Temps => M_Temps
On obtient à la fin de cette étape des phrases avec des tags aux mots importants. Par exemple, la phrase "Le temps de Paris" devient "Le M_temps de V_Paris".*
Ensuite, on applique les fichiers de règles. Cette fois-ci, le but est de détecter les mots avec des tags, et de renvoyer un résultat avec un format bien précis, compréhensible par le service.
Pour cela, on applique des règles du type : M_%M1% # V_%V1% = METEO[%V1%]
Cela veut dire que si la phrase contient un mot tagué par "M_" et un deuxième tagué par
"V_", alors on retourne le résultat METEO[
L'architecture d'un service en langage naturel

| Les outils >> |