Le Web Sémantique
Technologies
Vue d'ensemble
Le schéma présenté ci-dessous est la formalisation graphique des différentes briques technologiques composant le Web sémantique.

Voici un bref descriptif de ce qui compose ce layer cake :
- A l'image des DTD pour XML: RDF schema permet de partager des cadres communs.
- Un langage de conversion pour permettre l'alignement entre les différents schémas RDF;
- Une couche de logique pour réaliser des inférences;
- Un langage pour assurer l'accès aux données;
- Un langage pour effectuer l'alignement de données;
- Un langage de requêtes génériques pour RDF qui offre les mêmes caractéristiques de base que SQL;
- Un principe de signature numérique pour permettre l'identification couplé au langage d'accès aux données.
XML est le support de sérialisation sur lequel s'appuient RDF et OWL pour définir des structures de données et les relations logiques qui les lient. (Le 10 Février 2004, le W3C publie les recommandations RDF et OWL)
Nous allons pouvoir exprimer, structurer et questionner des concepts complexes à l'aide de RDF, OWL et SPARQL, là où jusqu'à présent, nous avions recours aux bases de données relationnelles.
RDF

Développé par le W3C, le Resource Description Framework (RDF) est un modèle de graphe destiné à décrire de façon formelle les ressources Web et leurs métadonnées, afin de permettre le traitement automatique de telles descriptions.
Un document structuré en RDF est un ensemble de triplets (sujet, prédicat, objet) :
- Le sujet représente la ressource à décrire.
- Le prédicat représente un type de propriété applicable à cette ressource.
- L'objet représente une donnée ou une autre ressource.
Le sujet, et l'objet dans le cas où c'est une ressource, peuvent être identifiés par une URI ou être des noeuds anonymes. Le prédicat est nécessairement identifié par une URI.
RDF est donc simplement une structure de données constituée de noeuds et organisée en graphe.
Un document RDF ainsi formé correspond à un multi-graphe orienté étiqueté (lien).
Chaque triplet correspond alors à :
- un arc orienté dont le label est le prédicat
- le noeud source est le sujet
- le noeud cible est l'objet
La sémantique d'un document RDF peut être exprimée en théorie des ensembles et en théorie des modèles en se donnant des contraintes sur le monde qui peuvent être décrites en RDF. RDF hérite alors de la généricité et de l'universalité de la notion d'ensemble. Cette sémantique peut être aussi traduite en formule de logique du premier ordre, positive, conjonctive et existentielle :
{sujet, objet, prédicat} ⇔ prédicat(objet, sujet)
ce qui est équivalent à :
∃ objet, ∃ sujet tq prédicat(objet, sujet)
Le {sujet, prédicat, objet} peuvent être vu comme {sujet, verbe, complément}
Cela donne pour la phrase :
Tim Berners-Lee est une personne
<=>
<http://www.w3.org.People/Berners-Le/card#i> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://xmlns.com/foaf/0.1/Person>
(les couleurs représentent les trois couleurs du logo du RDF dessiné par le W3C)
Les documents RDF peuvent être écrits en différentes syntaxes, y compris en XML. Mais RDF en soi n'est pas un dialecte XML. Il est possible d'avoir recours à d'autres syntaxes pour exprimer les triplets. Bien que RDF/XML — sa version XML proposée par le W3C — ne soit qu'une sérialisation du modèle, elle est souvent appelée RDF. Un abus de langage désigne à la fois le graphe de triplets et la présentation XML qui lui est associée.
Passons à l'exemple :
L'expression de l'assertion " Paris est en France " peut se faire par le biais de l'écriture d'un triplet RDF, que l'on peut représenter sous la forme d'un graphe sujet-prédicat-objet :

Nous avons ici deux noeuds, "Paris" et "France", reliés par un arc nommé "est_situé_en".
En d'autres termes :
- Paris : est ce qu'on appelle une ressource, ou encore un sujet, une source.
- Est_situé_en : est ce qu'on appelle un prédicat ou encore une propriété .
- France : est ce qu'on appelle une valeur ou encore un objet, une cible (target)
La sérialisation en RDF-XML de l'assertion "Paris est située en France" pourrait s'écrire de la manière suivante :
<rdf:Description about="#paris">
<schema:pays>France</schema:pays>
</rdf:Description>Un document RDF peut être chargé dans un éditeur d'ontologies "SWOOP" ou des Frameworks sémantique "SESAME, JENA" pour être visualisé.
Passons maintenant à la définition des espaces de noms pour RDF.
OWL

OWL (Web Ontology Language) est un langage basé sur RDF. Il enrichit le modèle des RDF Schemas en définissant un vocabulaire riche pour la description d'ontologies complexes.
OWL est basé sur une sémantique formelle définie par une syntaxe rigoureuse. Il existe trois versions du langage : OWL Lite, OWL DL, et OWL Full.
L'objectif d'une ontologie Web est de modéliser un ensemble de connaissances dans un domaine donné, d'associer et de relier les différents concepts de ce domaine, et tout cela de manière compréhensible par les machines.
Les ontologies décrivent généralement :
- Individus : les objets de base
- Classes : ensembles, collections, ou types d'objets
- Attributs : propriétés, fonctionnalités, caractéristiques ou paramètres que les objets peuvent posséder et partager
- Relations : les liens que les objets peuvent avoir entre eux
- Evénements : changements subis par des attributs ou des relations
OWL utilise les URIS (URI, URN, URL) pour nommer et RDF pour créer des liens.
Ainsi, les ontologies Web possèdent les avantages suivants :
- Capacité d'être distribuées au travers de nombreux systèmes
- Mise à l'échelle pour les besoins du Web
- Compatibles avec les standards Web pour l'accessibilité et l'internationalisation
- Ouvertes et extensibles
OWL s'appuie sur un modèle et un schéma RDF pour ajouter plus de vocabulaire dans la description de propriétés et de classes, comme par exemple :
- les relations entre classes
- la cardinalité
- l'égalité
- une typographie plus riche des propriétés
- des caractéristiques de propriétés
- et des classes énumératives
Comparaisons entre RDF Schema et OWL :
OWL et RDF Schema sont tous deux des vocabulaires RDF permettant de définir des vocabulaires.
RDF Schema définit le plus petit nombre de notions et de propriétés nécessaires à la définition d'un vocabulaire simple, essentiellement :
- les notions de classe, ressource, littéral
- les propriétés de sous-classe, de sous-propriété, de champ de valeur, de domaine d'application
OWL est un langage beaucoup plus riche qui, aux notions définies par RDF Schema, ajoute les propriétés de classe équivalente, de propriété équivalente, d'identité de deux ressources, de différence de deux ressources, de contraire, de symétrie, de transitivité, de cardinalité, etc., permettant ainsi de définir des rapports complexes entre des ressources.
exemple:
Si nous reprenons l'exemple précédent sur Paris, OWL permet d’ajouter à cette assertion des contraintes logiques qualifiants ; par exemple, le fait que le sujet associé au prédicat "est_situé_en" doit être une ville, et son objet un pays.
Par l’expression de nombreux faits simples tels que le triplet écrit ci-dessus, il est possible de décrire des ensembles d’informations très variés : les relations entre des individus, les produits d’un catalogue, des recettes de cuisine, etc. Reliés les uns aux autres, les différents triplets forment alors un graphe RDF, qui représente de manière extensible les informations d’un domaine donné de connaissance, et avec un niveau de précision optimisable à volonté.
Il peut, par exemple, être intéressant de définir ensuite ce qu’est une ville (« une ville est une entité administrative », « une ville a un certain nombre d’habitants », etc), ou même de relier le concept de ville défini dans notre ontologie au même concept, mais décrit dans une autre ontologie déja existante.
En OWL, une manière simple de décrire le fait que la ville "Paris" se trouve dans le pays "France" pourrait être :
<!-- définition des classes "ville" et "pays" -->
<owl:Class rdf:ID="Ville" />
<owl:Class rdf:ID="Pays" />
<!-- définition de la propriété « se_trouve_en » -->
<owl:ObjectProperty rdf:ID="seTrouveEn">
<rdfs:domain rdf:resource="#Ville" />
<rdfs:range rdf:resource="#Pays" />
</owl:ObjectProperty>
<!-- création de "France" -->
<Pays rdf:ID="France">
<nomPays>France</nomPays>
</Pays>
<!-- création de "Paris", qui se trouve en France -->
<Ville rdf:ID="Paris">
<nomVille>Paris</nomVille>
<seTrouveEn rdf:resource="#France" />
</Ville>L'emploi d'ontologies et de RDF au sein d'une application Web ou autre permet de partager à l'échelle d'internet les documents et les données ainsi créés.
Mais comment accéder avec aisance à un dépot sémantique?
C'est le rôle joué par SPARQL (qui se prononce "sparkle", Protocol and RDF Query Language ).
SPARQL

SPARQL est un protocole (W3C du 15 janvier 2008) et un langage de requêtes qui permet d'exploiter l'approche sémantique des données RDF.
Il est doté :
- d'un langage de requêtes avec syntaxe basée sur des triplets
- d'un protocole d’accès comme un service Web (SOAP)
- d'un langage de présentation des résultats (XML)
Grâce à cette technologie d'interrogation, les utilisateurs peuvent se concentrer sur leur recherche plutôt que sur la technologie de base de données ou le format sur lesquels repose le stockage des données.
SPARQL cible donc l'interrogation de meta-données RDF, structure de base du Web sémantique.
Il fonctionne en parfaite synergie avec les autres technologies Web sémantique du W3C :
- RDF (Resource Description Framework) pour la représentation des données,
- RDFS (schéma RDF),
- OWL (Web Ontology Language) pour la création de vocabulaires
- GRDDL
Exemple de la syntaxe en triplets simplifiée avec des points d'interrogation pour marquer les variables:
?x rdf:type ex:PersonneLangage de patterns à matcher:
select ?sujet ? propriete ?valeur where
{?sujet?propriete?valeur}Le pattern est par défaut une conjonction de triplets
{ ?x rdf:type ex:Personne .
?x ex:nom ?nom }Il existe deux formes possibles pour la présentation des résultats:
- le binding i.e. la liste des valeurs sélectionnées pour chaque réponse rencontrée (format XML stable ; bien avec XSLT) ;
- les sous graphes des réponses rencontrées en RDF (format RDF/XML, bien pour applications utilisant RDF)
Avantages du SPARQL :
Dans le cas des services Web 2.0 actuels, les Web services sont certes disponibles, mais ne sont pas normalisés, il faut donc connaître les méthodes du Web services et la structure des données pour les interroger.
Avec SPARQL, nous n'avons pas besoin de connaître a priori la structure et le contenu des données pour pouvoir les interroger. En effet, Sparql permet d'interroger n'importe quel composant d'un triplet qui a la forme Sujet-Prédicat-Objet.
SPARQL : une API universelle d'accès aux données
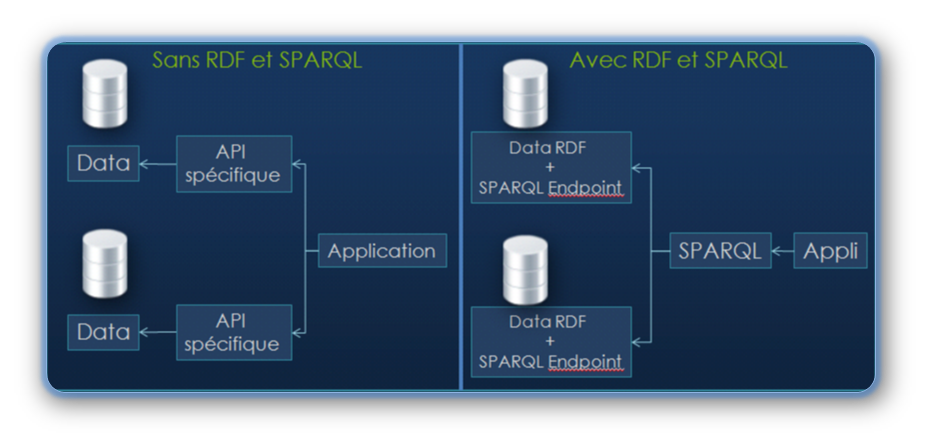
Exemples :
Si on veut connaître tous les triplets qui composent un fichier RDF, sans rien connaître a priori des ressources décrites, des propriétés utilisés ou du contenu, on effectue la requête suivante :
SELECT ?sujet ?predicat ?objet
WHERE {
?sujet ?predicat ?objet
}Le nom des variables est précédé d'un point d'interrogation.
La ligne SELECT permet de sélectionner l'ensemble des tuples, ou lignes de variables (sujet, predicat, object) correspondant aux contraintes de la clause WHERE.
Maintenant, on veut connaître tous les prédicats/propriétés pour décrire la ressource Paris ou pour lesquels la ressource Paris est l'objet dans Dbpedia :
SELECT DISTINCT ?predicat
WHERE {
{<http://dbpedia.org/resource/Paris> ?predicat ?objet.}
UNION {
?sujet ?predicat <http://dbpedia.org/resource/Paris>.
}
}Maintenant que l'on connaît les propriétés décrivant la ressource Paris, on veux connaître toutes les personnes qui sont nées à Paris :
SELECT DISTINCT ?personne
WHERE {
{?personne <http://dbpedia.org/property/cityofbirth> <http://dbpedia.org/resource/Paris>.}
UNION {
?personne <http://dbpedia.org/property/birthPlace>
<http://dbpedia.org/resource/Paris>.
}
UNION {
?personne <http://dbpedia.org/property/placeOfBirth>
<http://dbpedia.org/resource/Paris>.
}
}RDF et SPARQL sont suffisamment génériques pour effectuer à peu près tous les types d'interrogations sur un entrepôt de données avec une seule méthode et un seul langage de requêtes.
Et pour extraire toutes les autres données XML non stockées dans un réservoir ?
GRDDL

C'est là qu'intervient GRDDL, qui est un mécanisme destiné à glaner des descriptions de ressources dans les dialectes des langages (à prononcer "griddeul", Gleaning Resource Descriptions from Dialects of Languages).
C'est une technique d'obtention de données RDF dans les documents XML et en particulier dans les pages XHTML.
Pour relier explicitement les données dans ce document au modèle de données RDF, l'auteur doit faire deux modifications :
- Ajouter un attribut "profile" à l'élément head pour indiquer que son document contient des métadonnées GRDDL.
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="fr" lang="fr">
<head profile="http://www.w3.org/2003/g/data-view">
<title>Le Web Sémantique</title>
</head>
<body>- Ajouter un élément "link" contenant la référence de la transformation GRDDL spécifique pour convertir le code HTML en RDF.
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="fr" lang="fr">
<head profile="http://www.w3.org/2003/g/data-view">
<title>Le Web Sémantique</title>
<link rel="transformation" href="http://www.w3.org/2002/12/cal/glean-hcal"/>
</head>
<body>Passons maintenant à un cas d'utilisation complet avec RDF et SPARQL.
Cas d'utilisation
Voici une requête SPARQL retournant une liste de photos avec le nom de la personne qu'elles représentent et une description, à partir d'une base de données de type RDF utilisant l'ontologie (vocabulaire) FOAF (une des plus connues et utilisées pour décrire les personnes et les liens entre elles).
Extrait du graphe RDF (écriture XML) d'exemple :
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:foaf="http://xmlns.com/foaf/0.1/"
xmlns:rss="http://purl.org/rss/1.0/"
xmlns:dc="http://purl.org/dc/elements/1.1/">
<foaf:Person rdf:about="http://www-igm.univ-mlv.fr/~duris/">
<foaf:name>Etienne Duris</foaf:name>
<foaf:img rdf:resource="http://www-igm.univ-mlv.fr/~duris/maPomme.jpg"/>
<foaf:knows rdf:resource="http://www-igm.univ-mlv.fr/~dr/"/>
</foaf:Person>
<foaf:Person rdf:about="http://www-igm.univ-mlv.fr/~dr/">
<foaf:name>Dominique Revuz</foaf:name>
<foaf:img rdf:resource="http://www-igm.univ-mlv.fr/~dr/drWia97.jpg"/>
<foaf:knows rdf:resource="http://www-igm.univ-mlv.fr/~duris/"/>
</foaf:Person>
<foaf:Image rdf:about="http://www-igm.univ-mlv.fr/~duris/maPomme.jpg">
<dc:description>Photo d'identité d'Etienne Duris</dc:description>
</foaf:Image>
<foaf:Image rdf:about="http://www-igm.univ-mlv.fr/~dr/drWia97.jpg">
<dc:description>Photo d'identité de Dominique Revuz</dc:description>
</foaf:Image>
</rdf:RDF>La requête SPARQL correspondante :
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
PREFIX dc: <http://purl.org/dc/elements/1.1/>
SELECT DISTINCT ?nom ?image ?description
WHERE {
?personne rdf:type foaf:Person .
?personne foaf:name ?nom .
?image rdf:type foaf:Image .
?personne foaf:img ?image .
?image dc:description ?description
}On remarque la déclaration des espaces de noms en début, suivis de la requête proprement dite.
La première ligne de la clause WHERE se lit : la variable personne est de type Person au sens de l'ontologie FoaF.
La seconde ligne permet de définir la variable nom en tant que propriété name de la variable personne.
Voici le résulat SPARQL :
<sparql xmlns="http://www.w3.org/2005/sparql-results#">
<head>
<variable name="nom"/>
<variable name="image"/>
<variable name="description"/>
</head>
<results ordered="false" distinct="true">
<result>
<binding name="nom">
<literal>Etienne Duris</literal>
</binding>
<binding name="image">
<uri>http://www-igm.univ-mlv.fr/~duris/maPomme.jpg</uri>
</binding>
<binding name="description">
<literal>Photo d'identité d'Etienne Duris</literal>
</binding>
</result>
<result>
<binding name="nom">
<literal>Dominique Revuz</literal>
</binding>
<binding name="image">
<uri>http://www-igm.univ-mlv.fr/~dr/drWia97.jpg</uri>
</binding>
<binding name="description">
<literal>Photo d'identité de Dominique Revuz</literal>
</binding>
</result>
</results>
</sparql>Sémantisons le Web

Enfin, pour terminer cette partie sur les technologies, voici les étapes actuelles permettant de sémantiser le Web :
- Créer des vocabulaires/ontologie (Protege)
- Mettre les données au format RDF
- Créer des données RDF (Morla ou Top Braid ou à la main)
- Transformer des donnés de XML vers RDF/XML avec XSL
- Transformer une base de données relationnelles en RDF (D2R server)
- Stocker les données dans un triplet store RDF
- Triplet store natif : Mulgara, AllegroGraph, BigOWLIM…
- BDR paramétrée pour indexer des données en RDF (Virtuoso, ARC, Oracle 11g, Sesame, 3store)
- Column store pour indexer des données en RDF : Cstore, HRDF
- Exploiter les données en RDF
- En Java : Jena
- En PHP : RAP
- EN C : Redland
- En python : RDFlib