Architecture Core i7
Processeurs
Fonctionnement
Un processeur est composé de deux grandes entités : l'Unité Arithmétique et Logique et l'Unité de Commande ou Unité de Controle.
L'unité de contrôle va, via différents objets comme le compteur ordinal, le registre d'instructions, le décodeur, le séquenceur, le PSW et d'autres registres,
préparer les données et envoyer l'instruction à l'UAL. Cette dernière va effectuer les calculs appropriés et retourner le résultat à l'UC.
Toutes ces instructions arrivent pour faire fonctionner les différents organes de l'ordinateur. Pour communiquer avec ces éléments le processeur
et les composants passent par des bus :
- bus d'adresses
- bus de données
- bus de commande
Le premier sert à faire transiter les demandes d'écriture et de lecture en mémoire, le bus de données sert à faire transister des données
(résultat d'instruction par exemple) et enfin le bus commande permet de faire transiter tout un ensemble de signaux permettant de gérer
le dialogue entre le microprocesseur et les autres composants.
Ces 3 bus doivent faire transiter tous les échanges entre le processeur et le reste de l'ordinateur.
Pipeline
Pour améliorer les performances du processeurs, plusieurs techniques sont possibles et parmi celle là le pipeline quasi intégrée dans chaque processeur. Comment ça marche ??
Tout d'abord, expliquons comment fonctionnerait un processeur sans Pipeline. Une instruction qui arrive est découpée en plusieurs étapes, disons 5 pour respecter un modèle standard.
- IF (Instruction Fetch) charge l'instruction à exécuter dans le pipeline.
- ID (Instruction Decode) décode l'instruction et adresse les registres.
- EX (Execute) exécute l'instruction (par la ou les unités arithmétiques et logiques).
- MEM (Memory), dénote un transfert depuis un registre vers la mémoire dans le cas d'une instruction du type STORE (accès en écriture) et de la mémoire vers un registre dans le cas d'un LOAD (accès en lecture).
- WB (Write Back) stocke le résultat dans un registre. La source peut être la mémoire ou bien un registre.
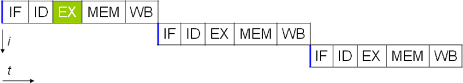
Pour effectuer une étape (on parle aussi d'étage), il faut un cycle d'horloge. Pour traiter une instruction, il faut passer par ces 5 étapes et ensuite le processeur passe à la prochaine instruction et ainsi de suite...
Ci dessus, nous avons 3 instructions qui arrivent, donc 3 instructions * 5 (étapes) = 15 étapes au total donc 15 cycles d'horloges pour executer ces 3 instructions.
Avec la technique du Pipeline, nous améliorons le débit d'instructions traitées. Comment ?
Comme vous pouvez le voir ci dessus, on attend (inutilement) qu'une instruction soit traitée entièrement. La technique du Pipeline permet de prendre en charge l'instruction suivante en commençant par charger les premiers étages libres.
Sur le schéma ci dessous, on peut voir qu'à :
à t=1 on va pouvoir charger le premier étage, le chargement de la première instruction.
à t=2 on décode la première instruction et on charge la seconde instruction.
à t=3 on execute la première instruction, on décode la 2ème et on charge la troisième.
à t=5 tous les étages sont occupés : la première instruction utilise l'étage de Write back, la deuxième l'étage MEM, la troisième l'étage EX etc...
etc...
à t=10 on a fini d'exécuter nos 5 instructions.
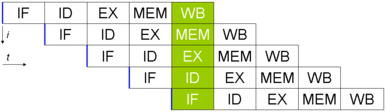
Ce que l'on peut vite comprendre, c'est que cette technique permet d'accélerer le traitement des instructions. En 9 cycles d'horloge, 5 instructions sont traitées alors que sans Pipeline, il faudrait 5*5= 25 cycles d'horlorge.
On augmente ainsi clairement les performances d'un processeur en mettant en place le pipeline.
En exploitant donc cette notion de pipeline, on peut donc se dire que l'on peut rajouter des pipelines pour pouvoir aller encore plus vite, c'est ce qui a été mis en place dans des processeurs dits superscalaires : on met en parallèle plusieurs pipelines pour multiplier les performances de façon linéaire.
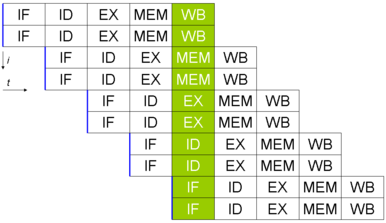
Ainsi, sur ce processeur superscalaire de degré 2 (pour 2 pipelines), on multiplie les performances par deux : on passe de 5 à 10 requêtes traitées en 9 cycles.
SMT
Pour, une fois de plus, améliorer les performances des ordinateurs, une nouvelle technique a été mise en place : le SMT.
Pour Simultaneous Multi Threading. Le but est d'augmenter le parallélisme des threads, explications :
Il a été remarqué que les processeurs pourraient être sous-exploité dans le sens où ils pourraient traiter encore plus d'instructions, mais ils ne sont
pas alimentés assez rapidement. Pour remédier à ce problème, le SMT se base sur le principe que non plus un mais plusieurs thread aliment le processeur en
instructions.
Ces threads partagent la mémoire (caches et registres) et le ou les pipelines. Ainsi il n'y a plus de temps perdu où le processeur ne travaille pas.