Le Data Mining
Le problème du badge
Utilisation de Weka
Après avoir importé notre fichier de données dans Weka, on obtient l'écran suivant :

Le graphique affiché représente en abscisse la longueur des noms, et en ordonnées le nombre de badges correspondant. La classification est logiquement faites sur les badges (+ ou -) et est représentée par les couleurs rouge et bleu.
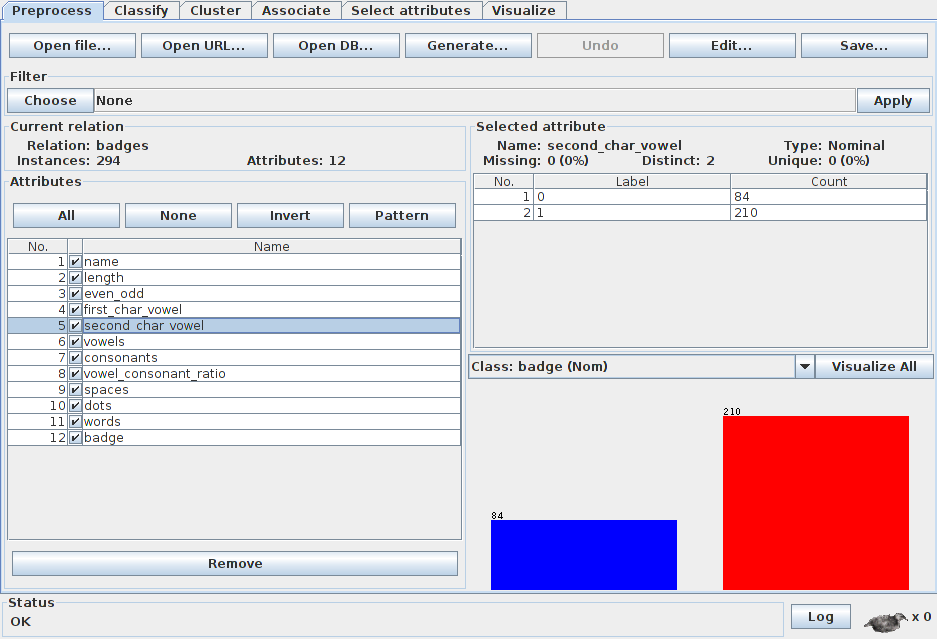
Cette fois, ce n'est plus la longueur du nom mais la nature de sa deuxième lettre (voyelle ou consonne) qui est représenté en abscisse. On remarque immédiatement que la répartition des couleurs est totalement dépendante de la nature de la deuxième lettre. Nous avons donc bien trouvé la fonction d'association entre nom et badge.
Il aurait été intéressant d'aborder un problème plus complexe et de s'intéresser à l'étape de choix du modèle, mais faute de temps je n'en ai pas eu la possibilité.
Le but étant de présenter succinctement le logiciel Weka, je vous propose cependant un écran supplémentaire, qui correspond à l'affichage graphique des résultats.
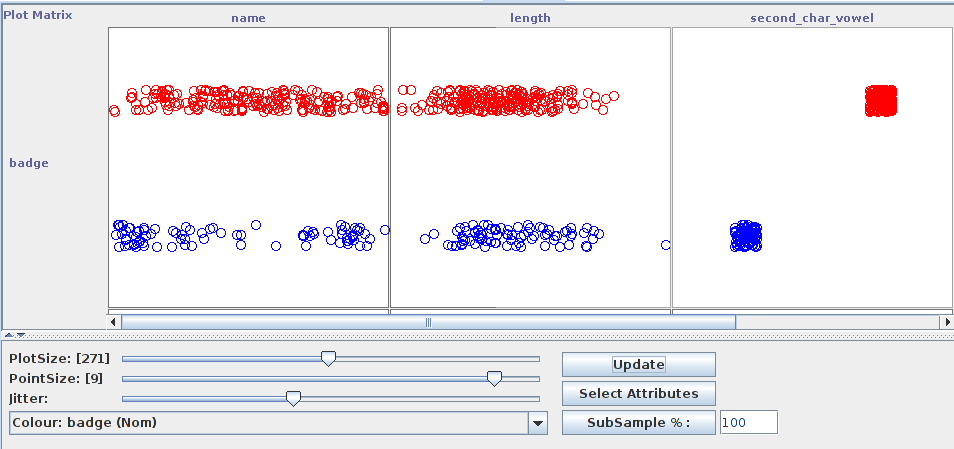
Ces graphiques représentent les relations entre les données en entrée. On s'intéresse aussi à la relation entre la donnée "badge" et les autres.
On remarque qu'il est possible d'effectuer différents réglages pour faciliter la lecture des graphiques (la gigue notamment, qui permet de visualiser des points qui se chevaucheraient complètement sinon).
Autres exemples
Beaucoup d'autres fichiers de données, notamment utilisables dans Weka sont disponibles ici
Expertise nécessaire
Bien qu'on puisse aisément comprendre certaines fonctionnalités de base de Weka, pour en faire une utilisation réellement utile dans le cadre du Data Mining, il s'avère absolument nécessaire d'avoir une compréhension des modèles mathématiques proposés, voire d'utiliser son propre modèle.