LMAX-Architecture
Le ring buffer
Au début, j'avais l'impression que le Disruptor était juste le tampon en anneau. Mais je me suis rendu compte que, bien que cette structure de données soit au cœur du modèle, l'inteligence du Disruptor réside avant tout sur le controle qu'il exerce dans la manière d'y accéder.
Qu'est-ce que c'est un tampon en anneau?
C'est un buffer donc on peut l'utilisez comme un tampon pour passer des choses d'un contexte (un thread) à un autre:
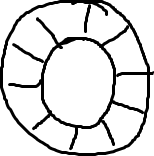
Donc, fondamentalement, c'est un tableau avec un pointeur vers le prochain emplacement disponible.
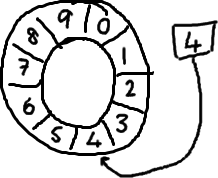
Comme on peut continuer à remplir la mémoire tampon, la séquence continue de s'incrémenter et s'enroule autour de l'anneau:
Pour trouver le prochain espace disponible dans le tableau on utilise une opération de modulo:
longueur du tableau séquence mod indice = array
Donc, pour le tampon circulaire ci-dessus (en utilisant la syntaxe Java "mod"): 12% 10 = 2. Facile.
Qu'est-ce qui est différent selon LMAX?
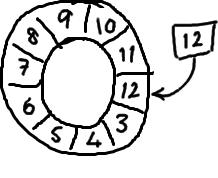
Si on regarde la page de Wikipedia sur les tampons circulaires, on voit une différence majeure à la façon dont il a été mis en place par LMAX - il y a un pointeur vers la fin. Nous avons seulement le numéro de séquence suivante disponible. LMAX avait besoin d'un magasin des messages que le service avait envoyé, donc quand un autre service a envoyé un message qu'ils n'avaient pas reçu , il serait en mesure de les renvoyer.
Le tampon en anneau semble idéal pour cela. Il stocke la séquence pour montrer où la fin de la mémoire tampon est, et si elle obtient un ack il peut rejouer tout de ce point à la séquence actuelle:
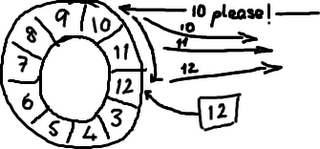
La différence entre le tampon en anneau comme LMAX l'a mis en œuvre, et les files d'attente que nous avions traditionnellement, c'est que LMAX ne consomme pas les articles dans la mémoire tampon - ils y restent jusqu'à ce qu'ils soient "overwritten". C'est pourquoi nous n'avons pas besoin de pointeur vers la fin qu'on peut voir dans la version Wikipedia. Décider si c'est OK pour envelopper ou non est géré en dehors de la structure de données elle-même (cela fait partie du comportement des producteurs et des consommateurs.
Qu'apportent ces différences?
Tout d'abord, il est plus rapide que quelque chose comme une liste chaînée, car c'est un tableau, et dispose d'un modèle prévisible d'accès. C'est agréable et CPU-friendly - au niveau du matériel les entrées peuvent être pré-chargé, pour que la machine n'est pas constamment à revenir à la mémoire principale pour charger l'élément suivant dans l'anneau.
Deuxièmement, c'est un tableau et vous pouvez le pré-allouer à l'avance, ce qui rend les objets effectivement immortels. Cela signifie que le garbage collector a à peu près rien à faire ici. Encore une fois, contrairement à une liste chaînée qui crée des objets pour chaque élément ajouté à la liste et nécessite donc un passage de GC à chaque fois.