Machine Learning : L'apprentissage par renforcement
Exemple
Mouse vs cliff
Prenons un exemple simple, imaginons une souris (Bleu) qui essaie d'obtenir un morceau de fromage (vert), en évitant une falaise (rouge), dans une pièce entouré de murs (noir). Si il tombe il doit recommencer.
Maintenant, comme expliqué précédemment, dans la politique de contrôle de Q-learning, la base de l'action à prendre est choisie en ayant la valeur de l'action la plus élevée. Cependant, il y a aussi une chance que certaines mesures aléatoires soient choisies; ceci est le mécanisme d'exploration intégré de l'agent.
Il y a donc une chance que la souris dise «oui, je vois le meilleur coup, mais ... non» et sauter par-dessus bord! Tout cela au nom de l'exploration. Cela devient un problème, parce que si la souris suivait une stratégie de contrôle optimale, cela serait tout simplement courir à droite le long du bord de la falaise jusqu’au fromage et le saisir.
Vous pouvez retrouver le code source sur SARSA vs Qlearn cliff
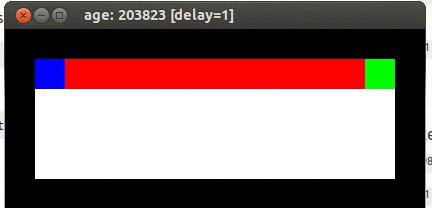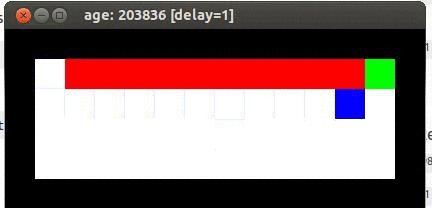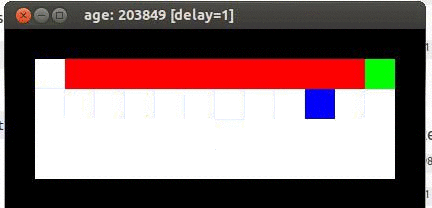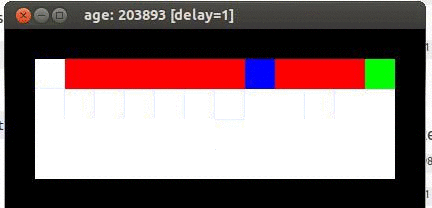
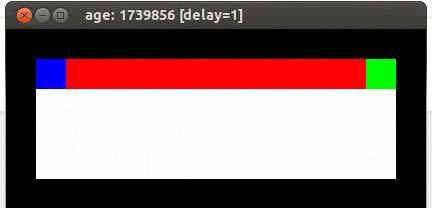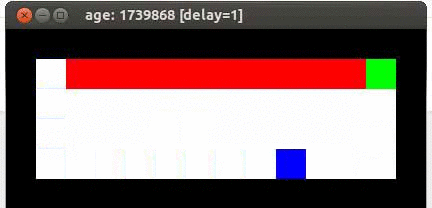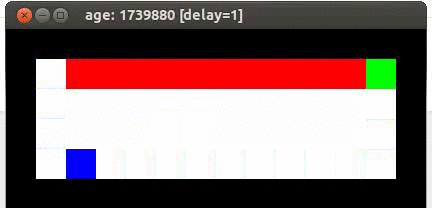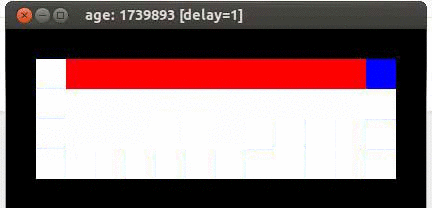
démonstration Q-Learning
Q-learning suppose que la souris suit la stratégie de contrôle optimal, de telle sorte que les valeurs déclenchant l'action convergent. Ceci, afin que le meilleur chemin soit : le long de la falaise. Voici une animation du résultat de l'exécution du code de Q-learning :
démonstration Sarsa
Le résultat est que la souris se retrouve à parcourir le long du bord de la falaise. Et, de temps en temps, elle saute en chute libre et meurt.
SARSA suppose que la souris suit la stratégie de contrôle la plus sûre, de telle sorte que les valeurs déclenchant l'action convergent afin que le meilleur chemin soit : le long du mur.