Subsequence Automaton
\( \def\sa#1{\tt{#1}} \def\dd{\dot{}\dot{}} \def\aSMot{\mathcal{SM}} \)Subsequences (or subwords) occurring in a word are useful elements to filter series of texts or to compare them. The basic data structure for developing applications related to subsequences is an automaton accepting them due to its reasonable size.
For a non-empty word $y$, let $\aSMot(y)$ be the minimal (deterministic) automaton accepting the subsequences of $y$. It is also called the Deterministic Acyclic Subsequence Graph (DASG). Below is the subsequence automaton of $\sa{abcabba}$. All its states are terminal and it accepts the set $$\{\sa{a},\sa{b},\sa{c},\sa{aa},\sa{ab},\sa{ac}, \sa{ba},\sa{bb},\sa{bc},\sa{ca},\sa{cb},\sa{aaa}, \sa{aab},\sa{aba},\sa{abb},\sa{abc},\dots\}.$$
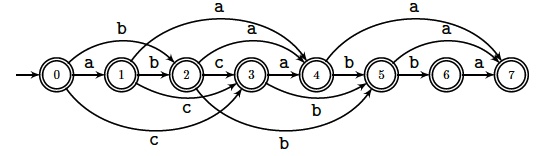
Subsequence automata are an essential structure to find words that discriminate two words because they provide a direct access to all their subsequences. A word $u$ distinguishes two distinct words $y$ and $z$ if it is a subsequence of only one of them, that is, if it is in the symmetric difference of their associated sets of subsequences.
The subsequence automaton of a word $y$ of length $n$ on an alphabet $A$ can be computed in time $O(n\times |A|)$ by the following algorithm.
\begin{algorithmic}
\FOR{each letter $a \in alph(y)$}
\STATE{$t[a]\leftarrow 0$}
\ENDFOR
\FOR{$i\leftarrow 0$ \TO $n-1$}
\FOR{$j\leftarrow t[y[i]]$ \TO $i$}
\STATE{$goto(j,y[i])\leftarrow i+1$}
\ENDFOR
\STATE{$t[y[i]]\leftarrow i+1$}
\ENDFOR
\end{algorithmic}